Get started

Do one of the following:
Right-click the target directory in the Workspace tool window, and select New from the context menu.
Press
Select Jupyter Notebook.
In the dialog that opens, type a filename, example.

A notebook document has the *.ipynb extension and is marked with the corresponding icon:
 .
.A newly created notebook opens in the editor. It contains one code cell. You can change its type with the cell type selector in the notebook toolbar:

To edit a cell, just click it.
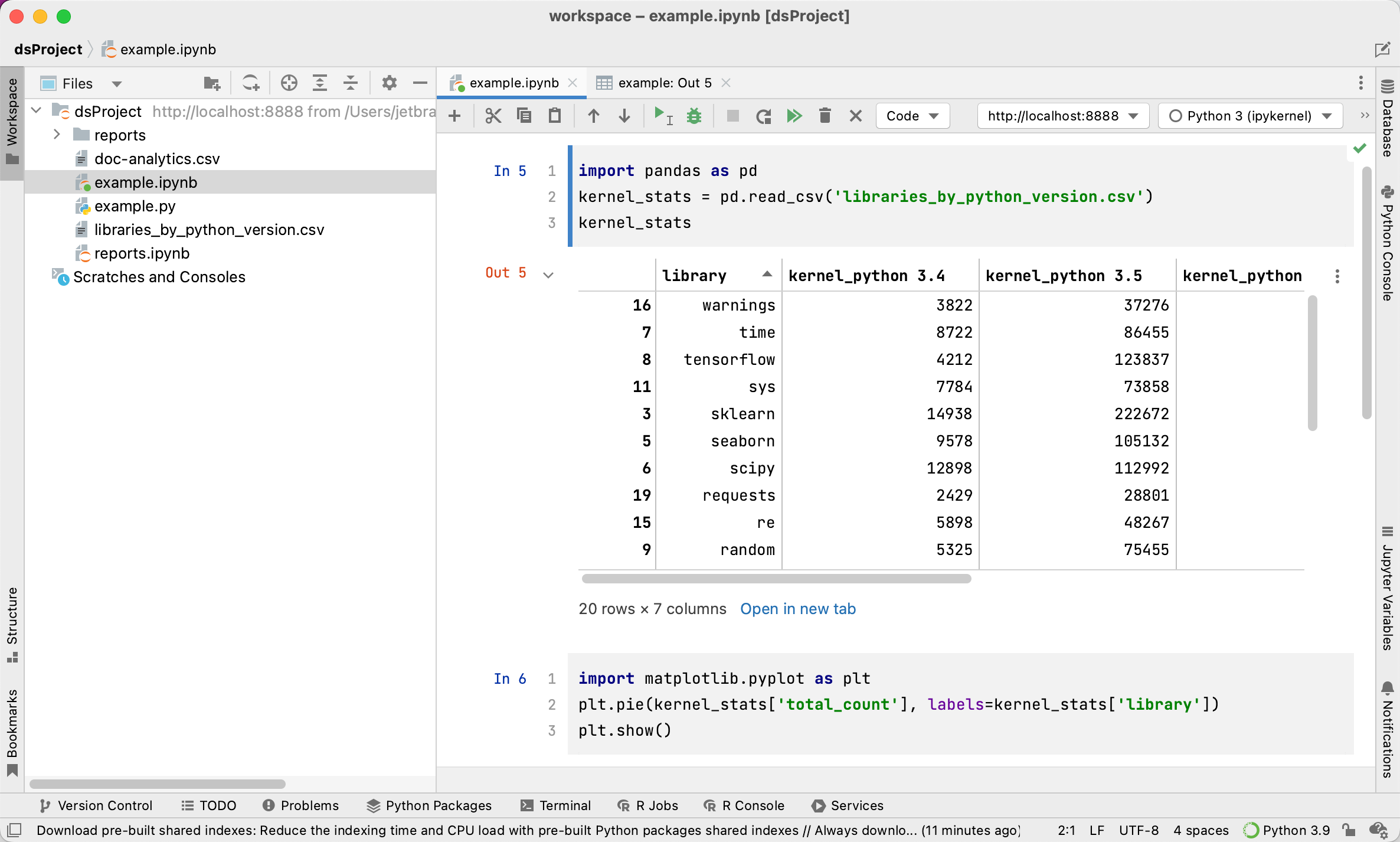
Put some pandas code in the first code cell:
import pandas as pd kernel_stats = pd.read_csv('libraries_by_python_version.csv') kernel_statsYou do not need to install the
pandaspackage in advance. Just click a highlighted line, press , and select a suggested fix for the missing import statement.This example uses the libraries_by_python_version.csv dataset. Download it from libraries_by_python_version.csv and save in the project directory.
Add more code or Markdown cells to your notebook. You can add a code cell after the very last cell, add a code cell or Markdown cell right after the selected cell, and insert a new cell after executing the selected cell. You can find these actions in the main menu item.
Let's put some
matplotlibcode to visualize the data frame of the first code cell.import matplotlib.pyplot as plt plt.pie(kernel_stats['total_count'], labels=kernel_stats['library']) plt.show()
Again, there is no need to preinstall
matplotlibandnumpy. Use to fix imports.

Once you’ve executed the cell, its output is shown below the code. You can click Open in new tab to preview tabular data in a separate tab of the editor.

Note that when you work with local notebooks, you don’t need to launch any Jupyter server in advance: just execute any cell and the server will be launched.
The Jupyter tool window shows the execution status. the current values of the variables in the Variables tab. You can preview the variables declared in your code in the Jupyter Variables tool windows.
Now execute the second cell. Its code depends on a variable from the first cell, so the order of cell execution is important.

You can copy the built plot or save it as an image. To execute all cells, click
 on the notebook toolbar.
on the notebook toolbar.
Click the gutter (the leftmost space in the editor) to set the breakpoints in the selected cell.
Press Shift+Alt+Enter for Windows/Linux or ⌥⇧⏎ for macOS. To debug the entire notebook, select from the main menu.

Use the stepping toolbar buttons to choose on which line you want to stop next and switch to the Debugger tool window to preview the variable values.

To open the server settings, select Configure Jupyter Server in the list of the Jupyter servers on the Jupyter notebook toolbar.

To connect to any running Jupyter server, select Configured Server and specify the server's path including a URL and a token.
In the Jupyter toolbar, from the list of the servers, select Switch to the current Jupyter Server to explicitly switch to the configured server.
Change the environment with the Python interpreter selector located in the lower-right corner of the DataSpell UI. Click it and select the target environment from the list.

Change Conda with Anaconda CLI
In the Terminal window, run the
lscommand in the <Conda Home>/envs directory (for example,/Users ) and select the target environment./jetbrains /.conda /envs Navigate to the bin directory of your anaconda installation (for example, anaconda3/bin).
Execute the
conda activate <env name> command(for example,conda activate my-conda-env).
Select Add interpreter in the Python interpreter selector.
In the Add Python Interpreter dialog, enter the name of the new environment, and specify the Anaconda base in the Conda executable field.

In the Python interpreter selector, choose the target environment and select Interpreter Settings.

Click
 to add a new package. Click the Conda package manager button (
to add a new package. Click the Conda package manager button ( ) to manage packages from the Conda repository. Otherwise, DataSpell will be using pip.
) to manage packages from the Conda repository. Otherwise, DataSpell will be using pip.Type a package name in the Search field and locate the target package. If needed, specify a package version.
Click Install. Close the window on the task completion.

