Das ist neu in DataGrip 2024.1
DataGrip 2024.1 ist da! Dieses erste große Upgrade des Jahres 2024 ist mit zahlreichen Verbesserungen ausgestattet. Schauen wir uns alle neuen Funktionen und Aktualisierungen an!
AI Assistant: Option zum Anhängen von Schemata nur für DataGrip

AI Assistant bietet Ihnen jetzt die Möglichkeit, die Qualität der generierten SQL-Abfragen zu verbessern, indem Sie im Chat ein Datenbankschema als Kontext angeben. Derzeit können nur Tabellen- und Spaltennamen angehängt werden und es gibt eine Höchstgrenze von 50 Tabellen.
Um diese Funktion nutzen zu können, müssen Sie AI Assistant die Erlaubnis erteilen, in Ihrem Projekt nach Datenbankobjekten zu suchen.

Sie können dies jedes Mal tun, wenn Sie ein neues Schema anhängen, oder Sie können einfach die Option im Popup Attach Schema aktivieren, die es AI Assistant erlaubt, sich Ihre Wahl zu merken. In diesem Fall wird die Einstellung Enable database context automatisch aktiviert:
Wichtig: Wenn die Einstellung Enable database context aktiviert ist, hat AI Assistant Zugriff auf alle Objektnamen aus allen Datenquellen.

Kontextmenü-Funktionen im Editor, wie z. B. Explain Code, verstehen jetzt das aktuelle Schema, wenn sie von Datenbankkonsolen aus aufgerufen werden.

Da AI Assistant Ihr Schema kennt, können Sie:
- Abfragen aus Anfragen in natürlicher Sprache generieren:

- Einblicke in Ihre Schemata gewinnen:

- Nicht-triviale Suchen durchführen:
Und das ist nur ein kleiner Ausschnitt dessen, was Sie tun können. Die Möglichkeiten sind endlos!
Mit Daten arbeiten
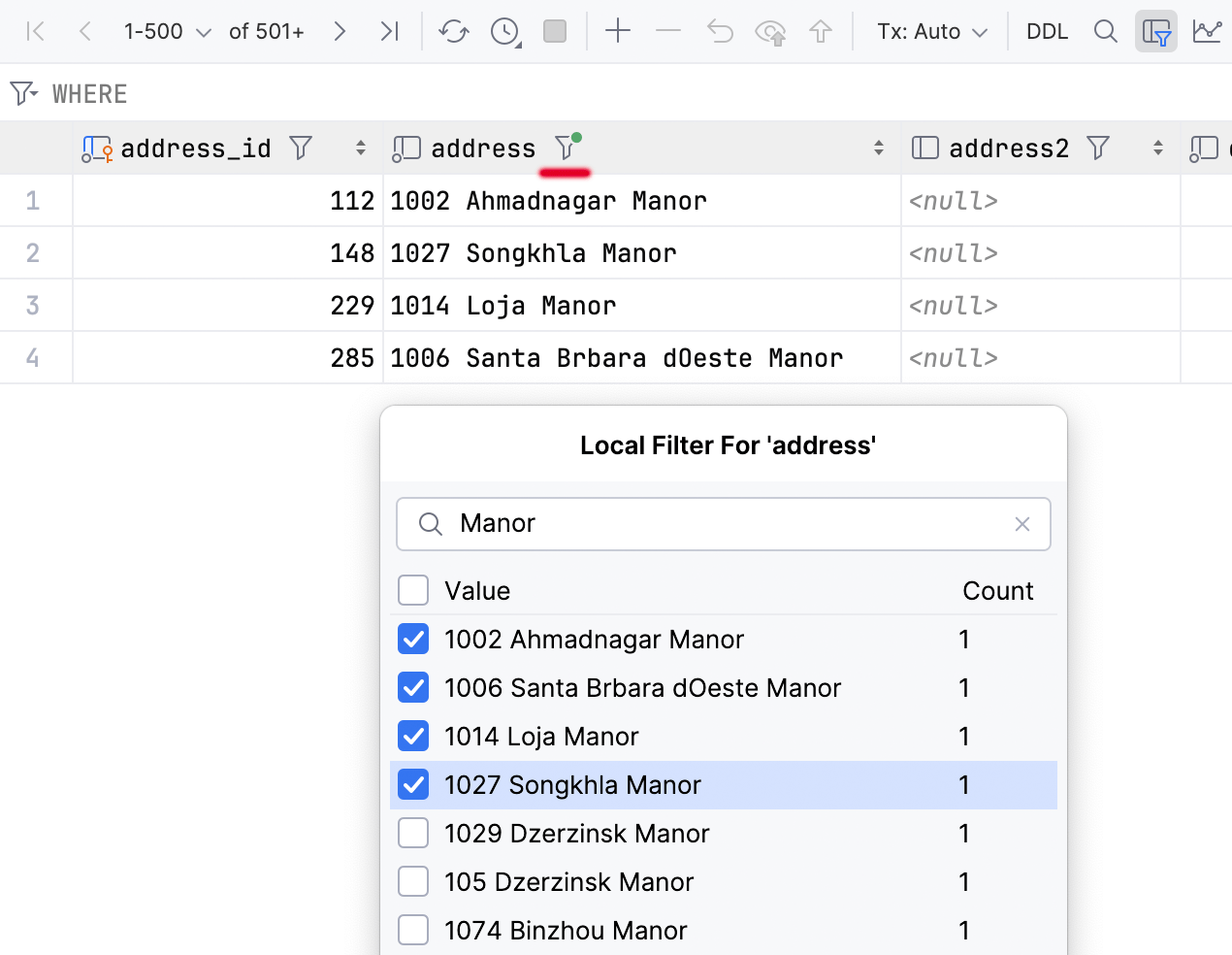
Lokale Filterung im Dateneditor
Eine lang erwartete Funktion ist endlich da: Sie können jetzt Zeilen nach Werten in Spalten filtern.
Diese Methode ist schnell, da sie keine Abfrage an die Datenbank erfordert. Es ist jedoch zu beachten, dass sich der Filter nur auf die aktuelle Seite auswirkt. Wenn Sie also mehr Informationen filtern möchten, können Sie einfach die Seitengröße ändern oder alle Daten abrufen.
Wenn Sie alle lokalen Filter für den aktuellen Dateneditor ausschalten möchten, deaktivieren Sie die Schaltfläche Enable Local Filter  .
.

Und vergessen Sie nicht die lokale Textsuchfunktion (Strg/Cmd+F)! Diese Funktion gibt es schon seit Jahrzehnten und sie kann immer noch nützlich sein, vor allem, wenn Sie nur eine ungefähre Vorstellung davon haben, wo sich die gesuchten Daten befinden.

Ansicht für einzelne Datensätze
Sie können sich jetzt auf einen einzelnen Datensatz im Dateneditor konzentrieren. Um eine Datensatzansicht zu öffnen, verwenden Sie die Tastenkombination Strg/Cmd+Umschalt+Enter oder die Schaltfläche Record View  in der Symbolleiste.
in der Symbolleiste.

Die Zellen in der Datensatzansicht können bearbeitet werden, wenn sie sich im Hauptgitter bearbeiten lassen.

Sie können das Layout auch auf zwei Spalten umstellen, wenn dies für Ihren Anwendungsfall sinnvoll ist:

Möglichkeit zum Verschieben von Spalten in CSV-Dateien
Ab 2024.1 können Sie Spalten im Dateneditor für eine CSV-Datei verschieben und die Änderungen werden auf die Datei selbst angewendet.

Weitere Funktionen für UUIDs
Als Reaktion auf eine Vielzahl von Anfragen, die wir in unserem Issue-Tracker erhalten haben, haben wir die Arbeit mit UUIDs vereinfacht:
- Wir haben eine neue Aktion hinzugefügt: Generate UUID.
- Es ist jetzt möglich, jede Spalte mit UUIDs zu bearbeiten, einschließlich derer, die durch
binary(16),blob(16)und ähnliche Typen dargestellt werden. - Werte in UUID-Spalten können jetzt während der Bearbeitung überprüft werden. PostgreSQL
Vereinfachte Sitzungen
In den letzten Jahren haben wir viele Rückmeldungen von Benutzer*innen erhalten, die sagen, dass sie das Konzept der Sitzungen nicht verstehen und dass diese Funktion erheblich zur Lernkurve von DataGrip beigetragen hat. Hier sind einige Beispiele:
Das projektorientierte Modell mit separater Konsolensitzung ist übertrieben. Dieses Modell macht das Öffnen und Ausführen einer einfachen SQL-Datei zu einer echten Herausforderung. Wenn ich nur ein Skript öffnen und ausführen möchte, muss ich zuerst ein Projekt erstellen, dann die Datei zum Projekt hinzufügen, dann eine Konsole öffnen, dann eine Sitzung öffnen und dann die Datei an die Sitzung anhängen. Was für ein Riesenärger.
Wenn Sie früher mit SQL Server Management Studio gearbeitet haben, ist die Benutzeroberfläche von DataGrip viel komplexer. In SSMS haben Sie im Grunde nur Server, Abfragen und Ergebnisse. In DataGrip gibt es Sitzungen, Konsolen und temporäre Hilfsdateien usw. usw., wodurch das Tool für neue Benutzer*innen viel weniger intuitiv ist.
Die Benutzeroberfläche ist teilweise klobig und unübersichtlich. Wenn ich eine Konsole auswählen muss, auf der ein Skript ausgeführt werden soll, ist mir nicht ganz klar, warum ich das tun muss oder was die Auswirkungen der Auswahl sind. Das sollte eigentlich nicht das Standardverhalten sein.
In DataGrip ist „Sitzung“ ein technischer Begriff, der sich auf den Container für eine Verbindung bezieht. Mit anderen Worten: Verbindungen können innerhalb einer Sitzung aufgebaut, beendet und wiederhergestellt werden. Für jede Verbindung gibt es eine Sitzung.
Die Möglichkeit, Sitzungen anzuhängen, ist ein leistungsfähiger Mechanismus, aber in den meisten Fällen müssen die Benutzer*innen nur den Kontext (Datenquelle und Datenbank oder Schema) für die auszuführenden Abfragen festlegen.
Ab Version 2024.1 müssen Benutzer*innen nicht mehr manuell auswählen, in welcher Sitzung Abfragen ausgeführt werden sollen. Dies gilt nun für alle Abfragenarten. Unter der Haube werden immer noch Sitzungen verwendet, aber Sie müssen sich keine Gedanken mehr um sie machen. Schauen wir uns nun genauer an, wie sich diese Änderung auf die wichtigsten Anwendungsfälle von DataGrip auswirkt.

Anhängen und Wechseln von Datenquellen
Um eine Datei anzuhängen, müssen Sie jetzt nur noch die Datenquelle und nicht mehr die Sitzung auswählen. Nachdem Sie die Datenquelle ausgewählt haben, wählen Sie das Schema.

Wechseln von Sitzungen
Die Aktion Switch Session erscheint jetzt nur noch im Kontextmenü des Clients im Toolfenster Services. Sie ermöglicht es Ihnen, die Sitzung nur innerhalb der aktuellen Datenquelle zu wechseln.

Ausführen von Funktionen
Sie müssen keine Sitzung mehr auswählen, bevor Sie eine Funktion starten. Im Fenster Execute Routine können Sie mit der Option Run from die Konsole oder Datei auswählen, von der aus die Funktion gestartet werden soll.
Codebearbeitung

Ausgerichteter Codestil für mehrzeilige INSERT-Anweisungen
Sie können jetzt mehrzeilige INSERT-Anweisungen so formatieren, dass ihre Werte ausgerichtet sind. Der Formatierer analysiert die Breite der Werte in jeder Spalte und wendet die am besten geeigneten Breiten an.

Um diese Funktion zu verwenden, aktivieren Sie die Option Align multi-row VALUES:

DataGrip kann mit Situationen umzugehen, in denen einige Werte viel länger sind als andere. Der Formatierer erkennt solche Werte und macht Ausnahmen für sie, indem er die verbleibenden Felder in die nächste Zeile verschiebt.

Dieses Verhalten wird durch diese drei Optionen gesteuert:

Spalten-Completion für GROUP-BY-Klauseln
DataGrip analysiert jetzt die in SELECT-Klauseln verwendeten Aggregate und fügt die entsprechenden Spaltenlisten in die Vorschläge der GROUP BY-Klausel ein.

Warnung für WHERE-TRUE-Klauseln
Wir haben unsere Unsafe query-Warnung erweitert. Sie warnt Sie jetzt, wenn Sie eine Abfrage mit der WHERE TRUE-Bedingung oder einer ihrer Variationen ausführen. Dies kann eine große Hilfe sein, wenn Sie diese Klausel gerne zu Debugging-Zwecken verwenden, aber gelegentlich vergessen, sie zu ändern!

Benutzerdefinierte Symbole zur Annahme von Vorschlägen
Sie können jetzt festlegen, welche Symbole Sie für die Annahme von Vorschlägen zur Code-Completion verwenden möchten, damit Sie SQL noch schneller schreiben können. Damit dies funktioniert, müssen Sie zwei Optionen aktivieren. Diese hier:

Und diese:

Diese Funktion kann besonders bei der Verwendung von Operatoren nützlich sein:

Angeheftete Zeilen im Editor
Um die Arbeit mit großen Dateien zu vereinfachen, haben wir im Editor angeheftete Zeilen eingeführt. Diese Funktion sorgt dafür, dass wichtige Strukturelemente, wie CREATE-Anweisungen, beim Scrollen am oberen Rand des Editors angeheftet werden. Auf diese Weise bleibt der Kontext immer im Blick, und Sie können sofort durch den Code navigieren, indem Sie auf eine angeheftete Zeile klicken.
Diese Funktion ist standardmäßig aktiviert. Sie können sie über ein Kontrollkästchen in Settings/Preferences | Editor | General | Appearance deaktivieren, wo Sie auch die maximale Anzahl der angehefteten Zeilen festlegen können.
Verschiedenes

Unterstützung für Redis-Stack-Modulbefehle Redis
DataGrip unterstützt jetzt die Befehle der vier wichtigsten Redis-Stack-Module: RedisJSON, RediSearch, RedisBloom und RedisTimeSeries. Diese Unterstützung erfordert auch die neue Version des Treibers: v1.5. Das RedisGraph-Modul ist veraltet und wird nicht mehr unterstützt. Diese Modulunterstützung ermöglicht Folgendes:
- Sie können Befehle von diesen Modulen senden und die Ergebnisse sehen.
- Befehle aus diesen Modulen werden richtig hervorgehoben.
- Die Schlüssel der von diesen Modulen bereitgestellten Typen werden im Datenbankexplorer angezeigt.

JSON-Dokumente
JSON-Dokumente werden jetzt in einem eigenen Ordner angezeigt. Sie können ihre Werte im Datenviewer anzeigen und den JSON-Pfad angeben.

Andere Datentypen
Schlüssel von Typen, die von den Modulen RedisTimeSeries und RedisBloom bereitgestellt werden, werden unter dem Ordner data structures angezeigt.

Unterstützung für externe, über Datenkataloge freigegebene Datenbanken Amazon Redshift
Externe Datenbanken, die über Datenkataloge geteilt werden, werden jetzt unterstützt. Ihr Inhalt wird nun introspektiert und die Completion ist für sie verfügbar.