Notebook
모든 데이터 과학 프로젝트의 중심에는 Jupyter Notebook이 있습니다. Datalore는 Jupyter Notebook으로 작업하기 위한 다양한 스마트 도구를 제공합니다. Python, SQL, R, Scala 및 Kotlin에 대한 스마트 코딩 지원에 활용하여 더 적은 노력으로 더 빠르게 이동하고 고품질 코드를 작성하세요. Datalore 에디터를 사용하면 연결된 데이터 소스, 자동 시각화, 데이터세트 통계, 보고서 작성기, 환경 관리자, 버전 관리 등을 포함한 모든 필수 도구에 빠르게 액세스할 수 있습니다.
Datalore에서 Jupyter Notebook을 만들기가 얼마나 쉬운지 보려면 아래 비디오를 시청하세요.
Jupyter 호환성

Datalore의 Notebook은 Jupyter와 호환 가능하므로 기존 IPYNB 파일을 업로드하여 Datalore에서 계속 작업할 수 있습니다. 또한 Notebook을 IPYNB 파일로 내보낼 수도 있습니다. 단, 데이터 연결 및 대화형 컨트롤은 내보낼 수 없습니다.
Python Notebook

PyCharm의 스마트 코딩 지원
Datalore는 PyCharm의 코드 분석 기능과 번들로 제공됩니다. Python Notebook은 최고의 코드 완성, 매개변수 정보, 검사, 빠른 수정 및 리팩터링 기능을 지원하므로 적은 노력으로 더 높은 품질의 코드를 작성할 수 있습니다.

인앱 문서
모든 메서드, 함수, 패키지 또는 클래스 관련 문서를 팝업에서 확인할 수 있습니다. Datalore는 문서가 필요한 곳에서 바로 문서를 표시합니다.

Conda 및 pip 지원
Datalore는 pip와 Conda를 모두 지원합니다. Pip는 빠르고 누구에게나 무료로 제공되지만, Conda는 비상업적 용도로 사용할 경우에만 무료입니다.
Kotlin, Scala 및 R Notebook
Datalore에서 Kotlin, Scala 및 R Notebook을 생성할 수 있습니다. 패키지 설치는 매직 명령어를 사용하여 수행할 수 있으며, 코드 작성 시 코드 완성이 제공됩니다.

SQL 셀
네이티브 SQL 셀을 추가하여 데이터베이스에 연결 후 쿼리할 수 있습니다. SQL 구문 강조 표시 기능뿐 아니라, 내부 검사한 데이터베이스 테이블을 기반으로 한 코드 완성 기능도 지원됩니다. 쿼리 결과는 자동으로 pandas DataFrame에 전송되며 Python에서 데이터 세트 작업을 계속 수행할 수 있습니다.

SQL 셀을 통해 DataFrame 쿼리
SQL 셀을 사용하면 데이터베이스에서와 마찬가지로 첨부된 문서에서 2D DataFrame과 CSV 파일을 쉽게 쿼리할 수 있습니다. Notebook에서 DataFrame을 찾아 선택하고 이를 SQL 셀의 소스로 사용하기만 하면 됩니다. 이 기능을 사용하면 SQL을 사용하여 다양한 소스의 데이터를 단일 DataFrame으로 병합하거나 복잡한 쿼리를 일련의 SQL 셀로 분할할 수 있습니다.

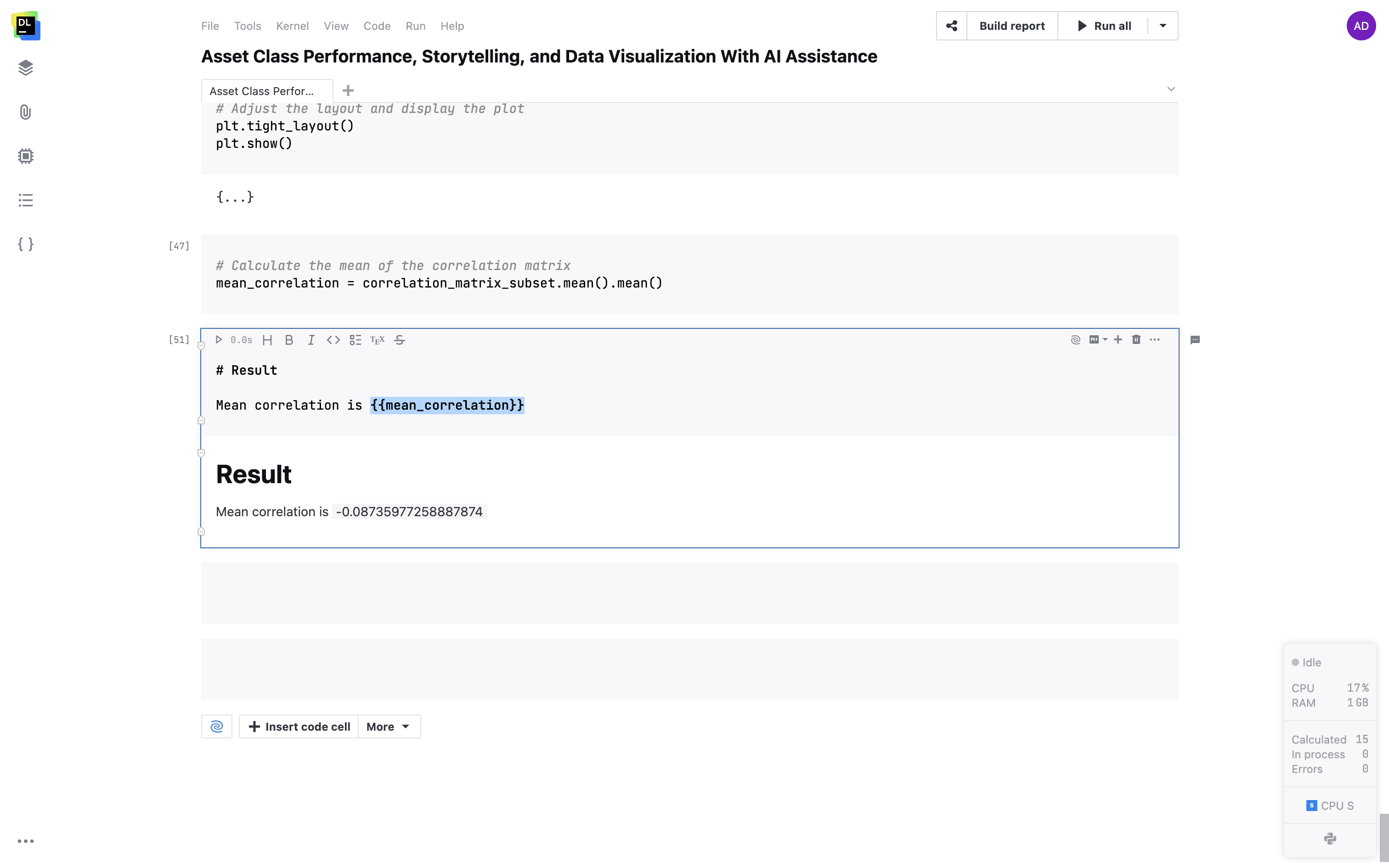
Markdown 셀의 변수 지원
Markdown 셀의 변수를 이중 중괄호로 임베딩하세요. 텍스트 내에서 변수가 동적으로 실시간 값으로 변환됩니다.
환경

패키지 관리자
Datalore는 통합 패키지 관리자가 함께 제공되어 환경을 재현할 수 있습니다. 패키지 관리자를 사용하면 새 패키지를 설치 및 관리하고, Notebook을 다시 열 때 필요한 패키지가 사전 구성되어 있도록 설정할 수 있습니다.
사용자 지정 기반 환경
사용자 지정 Docker 이미지로 여러 개의 기본 환경을 생성하세요. 모든 종속성, 패키지 버전 및 빌드 도구 구성을 사전에 구성할 수 있으므로 팀원이 수동으로 설치하고 패키지 버전을 동기화하는 시간을 아낄 수 있습니다.
Git 저장소의 패키지
Notebook에 Git 브랜치를 연결하여 Git 저장소에서 사용자 지정 pip 호환 패키지를 설치할 수 있습니다.
초기화 스크립트
Notebook이 시작되기 전 실행할 스크립트를 구성하세요. 필요한 모든 빌드 도구와 종속성을 지정할 수 있습니다.
시각화 자료
시각화 탭
모든 Pandas DataFrame용 Visualize(시각화) 탭에서 자동 시각화 옵션이 지원됩니다. 점, 선, 막대, 영역 및 상관 도표는 데이터 내용을 빠르게 이해하는 데 유용합니다. 데이터 세트가 큰 경우 자동으로 샘플링됩니다. 이후 모든 도표를 코드나 차트 셀로 추출하여 더 세부적으로 사용자 지정할 수 있습니다.
Python 시각화 패키지 모두 지원
원하는 패키지로 시각화 자료를 생성하세요. Datalore Notebook은 Matplotlib, plotly, altair, seaborn, lets-plot 및 기타 여러 패키지를 지원합니다.

차트 셀
프로덕션에서 즉시 이용 가능한 시각화 자료를 클릭 몇 번만으로 생성하세요. 공동 작업자에게 셀의 상태가 공유되므로 시각화 자료를 공동 작업할 수 있습니다.
대화형 테이블 출력
셀 출력에서 직접 Pandas DataFrames 및 SQL 쿼리 결과에 필터링과 정렬을 적용합니다. 표시할 열을 선택하고, 특정 열을 기준으로 데이터세트를 정렬하고, "같음" 및 "포함" 표현식을 기준으로 필터링하고, 데이터세트의 상단 또는 하단으로 쉽게 이동할 수 있습니다. 필터링 및 정렬을 완료한 후 코드 셀로 내보내기 옵션을 사용하여 Pandas 코드 스니펫을 생성하고 테이블 뷰가 재현될 수 있게 만드세요.

대화형 테이블에서 DataFrame 셀 편집
DataFrame에서 일련의 편집을 수행하기 위해 더 이상 CSV 파일을 다운로드할 필요가 없습니다. 대화형 테이블 내부의 셀 내용을 손쉽게 편집하고 Export to code(코드로 내보내기)를 클릭하여 Notebook에서 결과를 재현할 수 있습니다.

DataFrame 통계
한 번의 클릭으로 별도의 통계 탭 내에서 DataFrame에 대한 필수 설명적 통계를 얻을 수 있습니다. 범주 열의 경우 값 분포가 표시되고 숫자 열의 경우 Datalore가 최소값, 최대값, 중앙값, 표준 편차, 백분위수를 계산하고 0 및 이상값의 비율도 강조 표시합니다.

대화형 컨트롤
드롭다운, 슬라이더, 텍스트 입력 및 날짜 셀과 같은 대화형 입력을 Notebook 내에 추가하고 입력 값을 코드 내에서 변수로 사용합니다. 차트 셀로 정보를 시각화하고 메트릭 셀 내의 특정 숫자를 강조 표시합니다.

파일 업로더 대화형 제어
보고서 및 Notebook 소유자는 이제 공동 작업자가 로컬 컴퓨터에서 CSV, TXT 또는 이미지 파일을 업로드하도록 할 수 있습니다. 파일 업로드를 워크플로에 원활하게 통합하려면 파일 형식과 크기 제한을 설정하세요.

데이터베이스 셀로 내보내기
Notebook에서 직접 데이터베이스의 기존 테이블로 DataFrame을 내보낼 수 있습니다. DataFrame, 대상 데이터베이스, 스키마 및 테이블을 선택하여, 내보내기를 사용자 지정하세요. 예약 기능을 사용할 수도 있고, 내보내기를 자동화할 수도 있습니다.

IPyWidgets 지원
Datalore는 클래식 Jupyter 위젯 프레임워크인 IPyWidgets를 지원합니다. Python 코드로 대화형 컨트롤을 추가하고, 하나의 셀 출력에 여러 위젯을 결합하며, Notebook의 다음 부분에서 선택 항목을 변수로 사용합니다.

CSV 파일 미리보기
Datalore 에디터 내의 별도 탭에 있는 '첨부된 데이터' 탭에서 CSV 및 TSV 파일을 엽니다. 열 값을 정렬하고 파일 내용에 페이지를 매깁니다.

CSV 파일 편집
Datalore 에디터 내에서 바로 CSV 및 TSV 파일을 만들고 편집합니다. 처음부터 시작하여 새 파일을 만들거나 기존 파일의 내용을 편집할 수 있습니다.

터미널
에디터에서 터미널 창을 열고 .py 스크립트를 실행하고 표준 bash 명령어를 사용하여 에이전트, 환경 및 파일 시스템에 액세스할 수 있습니다.

변수 뷰어
한 곳에서 Notebook 변수와 기본 제공 매개변수 값을 탐색할 수 있습니다.

내부 버전 관리
기록 도구를 활용하여 언제든 변경 사항을 되돌릴 수 있는 사용자 지정 기록 체크포인트를 생성할 수 있습니다. 체크포인트를 탐색할 때 현재 버전의 Notebook과 선택한 버전의 Notebook 간 차이점을 확인할 수 있습니다.

컴퓨팅
CPU 및 GPU에서 Notebook 실행
Datalore를 사용하면 CPU 및 GPU에서 Notebook을 실행하고 UI에서 필요한 머신을 선택할 수 있습니다. 제공되는 리소스 유형 및 용량은 이용 중인 요금제에 따라 다릅니다. 자세한 정보는 여기를 참조해 주세요.

프라이빗 클라우드 및 온프레미스 시스템
이미 사용 중인 모든 유형의 서버 하드웨어를 Datalore에 연결하면 사용자가 Datalore 인터페이스를 통해 해당 하드웨어에 액세스할 수 있습니다.
재현 가능한 연구를 위한 Reactive 모드
Reactive 모드에서는 하향식 평가 순서와 수정된 셀 아래에 있는 셀의 자동 재계산이 적용됩니다. Notebook 상태는 각 셀의 평가 후에 저장되며 언제든지 복원할 수 있습니다.
백그라운드 컴퓨팅
백그라운드 컴퓨팅 기능을 활성화하면 브라우저 탭을 닫아도 Notebook이 계속 실행됩니다. User(사용자) 메뉴 또는 Admin(관리자) 패널에서 실행 중인 컴퓨팅 목록에 언제든지 액세스할 수 있습니다.
머신 사용량 보고서
각 머신의 실행 시간이 포함된 CSV 보고서를 다운로드할 수 있습니다. 이 정보는 가장 집중해서 작업한 프로젝트를 파악하는 데 도움이 될 수 있습니다.
Notebook 일정 계획
일정 계획을 사용하여 시간, 일, 주 또는 월 단위로 Notebook을 실행하고 게시된 보고서에 대한 정기적인 업데이트를 제공합니다. 사용자 인터페이스에서 일정 매개변수를 선택하거나 CRON 문자열을 사용합니다. 이메일을 통해 실행 성공 또는 실패 여부를 Notebook 공동 작업자에게 알립니다.

다중 노트북 일정
사용자 인터페이스를 통해 단일 Notebook에 여러 일정을 지정하고 관리하세요. 이 기능을 사용하면 사용자 지정 일정을 만들고 매시간, 매일, 매주 또는 특정 날짜에 Notebook을 실행할 수 있습니다. 고유한 요구 사항에 따라 다른 일정을 설정할 수 있어 리소스를 보다 효율적으로 할당하고 프로젝트 요구에 맞게 코드 실행 시기를 조정할 수 있습니다.

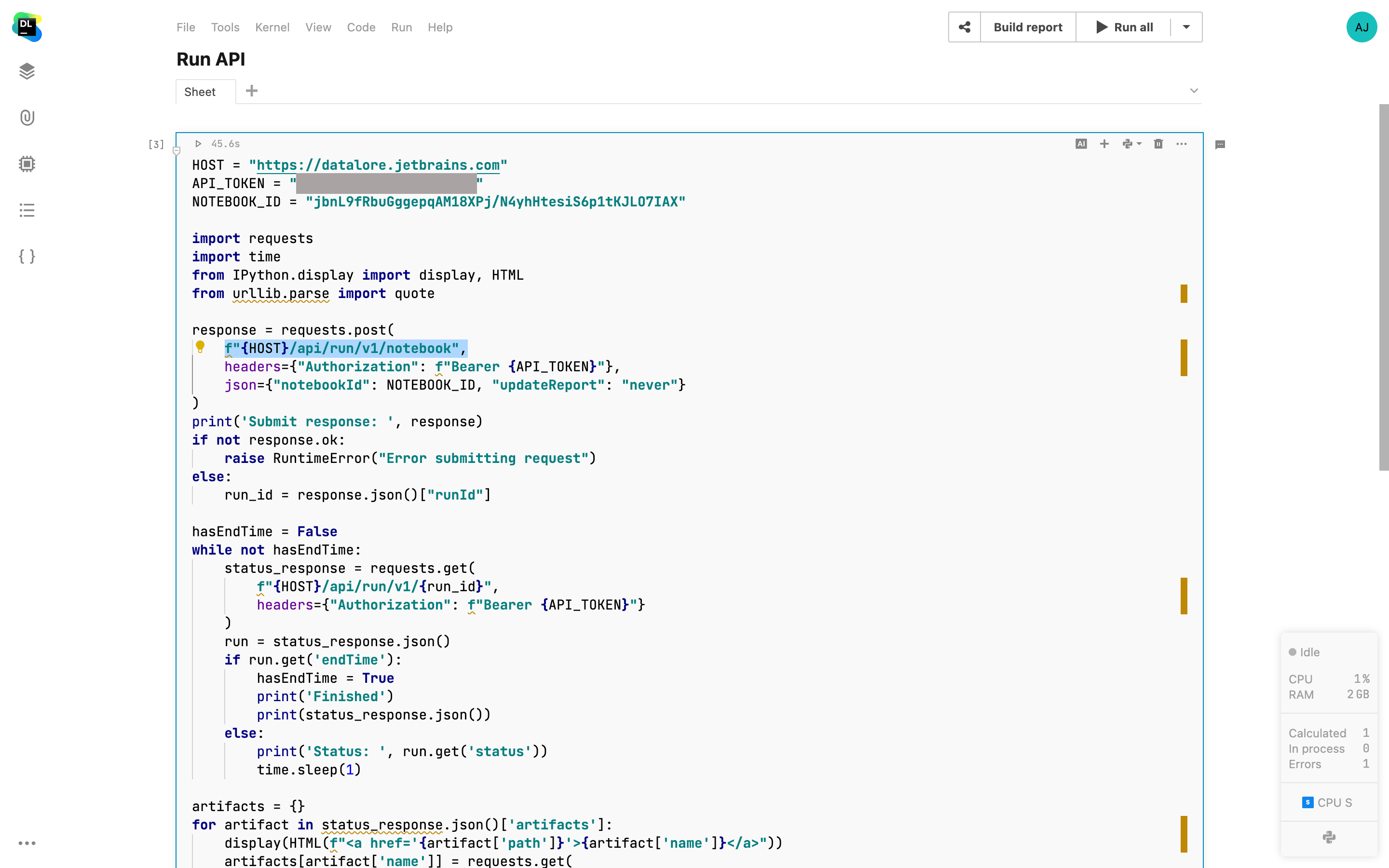
Datalore Run API
이제 Datalore Notebook 실행을 트리거하거나 API 호출로 보고서를 다시 게시할 수 있습니다. 이 기능은 외부 앱 및 내부 Datalore Notebook에서 필요에 따라 Notebook 재실행을 트리거할 수 있도록 예약 실행 기능이 확장된 것입니다. Scheduled run(예약 실행) 메뉴에서 실행 결과를 볼 수도 있습니다. API 사용 방법에 대한 자세한 내용은 여기에서 확인할 수 있습니다.
기본 R 패키지 지원
R Notebook의 경우 이제 Environment manager(환경 관리자) 탭 내 install.packages에서 지원하는 공개 및 비공개 R 패키지 저장소에서 패키지를 설치할 수 있습니다. Environment manager(환경 관리자)를 사용하면 Notebook이 실행되는 동안 환경 구성을 계속 유지할 수 있습니다. init.sh 또는 사용자 지정 에이전트 이미지에 .Rprofile 파일을 생성하여 사용자 지정 저장소를 구성할 수 있습니다.
클라우드 버전에서는 conda 설치가 기본적으로 유지되지만 Enterprise 고객은 R 커널을 사용하여 conda가 아닌 사용자 지정 기본 환경을 구성할 수 있습니다. 그러면 Environment manager 검색 결과에 conda 패키지가 표시되지 않습니다. 이러한 설치의 예는 여기에서 찾을 수 있습니다.

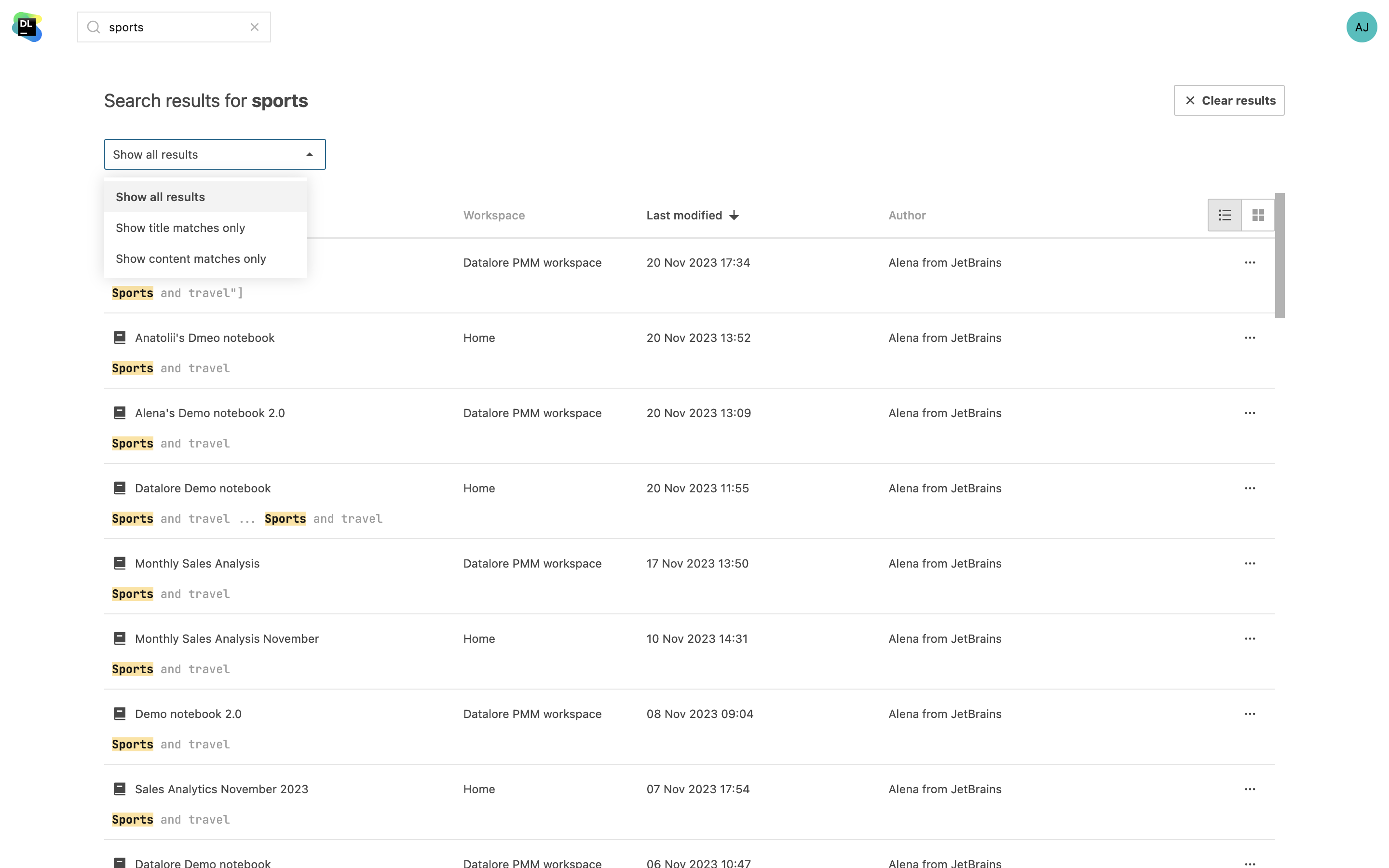
Notebook 콘텐츠 검색
특정 코드 섹션을 찾거나 작업공간의 모든 Notebook에서 필요한 정보를 찾으세요. 이제 Notebook 이름을 검색하는 외에도 변수 이름과 콘텐츠를 검색할 수 있습니다. 검색 결과에서 해당 쿼리가 강조 표시됩니다.