Notebooks
No coração de qualquer projeto de ciência de dados, está um notebook do Jupyter. O Datalore dá a você ferramentas inteligentes para trabalhar com notebooks do Jupyter. Pode confiar na assistência inteligente do Datalore à codificação em Python, SQL, R, Scala e Kotlin para ter mais agilidade e criar código de melhor qualidade com menos esforço. O editor do Datalore lhe dá acesso rápido a todas as ferramentas essenciais, incluindo fontes de dados anexadas, visualizações automáticas, estatísticas de conjuntos de dados, gerador de relatórios, gerenciador do ambiente, controle de versões e muito mais.
Assista ao vídeo abaixo para ver como é fácil criar notebooks Jupyter no Datalore:
Compatíveis com Jupyter

Os notebooks no Datalore são compatíveis com o Jupyter, o que significa que você pode carregar seus arquivos IPYNB existentes e continuar trabalhando com eles no Datalore. Além disso, você também pode exportar notebooks como arquivos IPYNB. Observe que conexões de dados e controles interativos não serão exportados.
Notebooks Python

Assistência de codificação inteligente do PyCharm
O Datalore vem com recursos de insights de código do PyCharm. Para notebooks Python, você obtém complementação de código de primeira classe, informações de parâmetros, inspeções, correções rápidas e refatorações que ajudam a escrever código de alta qualidade com menos esforço.

Documentação no aplicativo
Obtenha pop-ups de documentação para qualquer método, função, pacote ou classe. O Datalore mostrará a documentação exatamente onde você precisar.

Suporte para conda e pip
O Datalore suporta tanto o conda como o pip. O pip é rápido e gratuito para todos, enquanto o conda é gratuito apenas para uso não comercial.
Notebooks Kotlin, Scala e R
No Datalore, você pode criar notebooks Kotlin, Scala e R. Você pode usar magics para instalar pacotes e quando estiver escrevendo código terá complementação de código.

Células SQL
Adicione células SQL nativas para fazer consultas nas suas conexões de banco de dados. Além do realce de sintaxe para SQL, você também tem complementação de código com base em tabelas de banco de dados introspectadas. O resultado da consulta é automaticamente transferido a um DataFrame pandas, e você pode continuar trabalhando no conjunto de dados em Python.

Faça consultas em DataFrames via células SQL
Use células SQL para fazer consultas com facilidade em DataFrames 2D e arquivos CSV de documentos anexados, como você faria com bancos de dados. Basta navegar pelos DataFrames do seu notebook, escolher um e usá-lo como fonte para células SQL. Com esse recurso, você pode mesclar dados de várias fontes em um único DataFrame usando SQL ou dividir consultas complexas em uma sequência de células SQL.

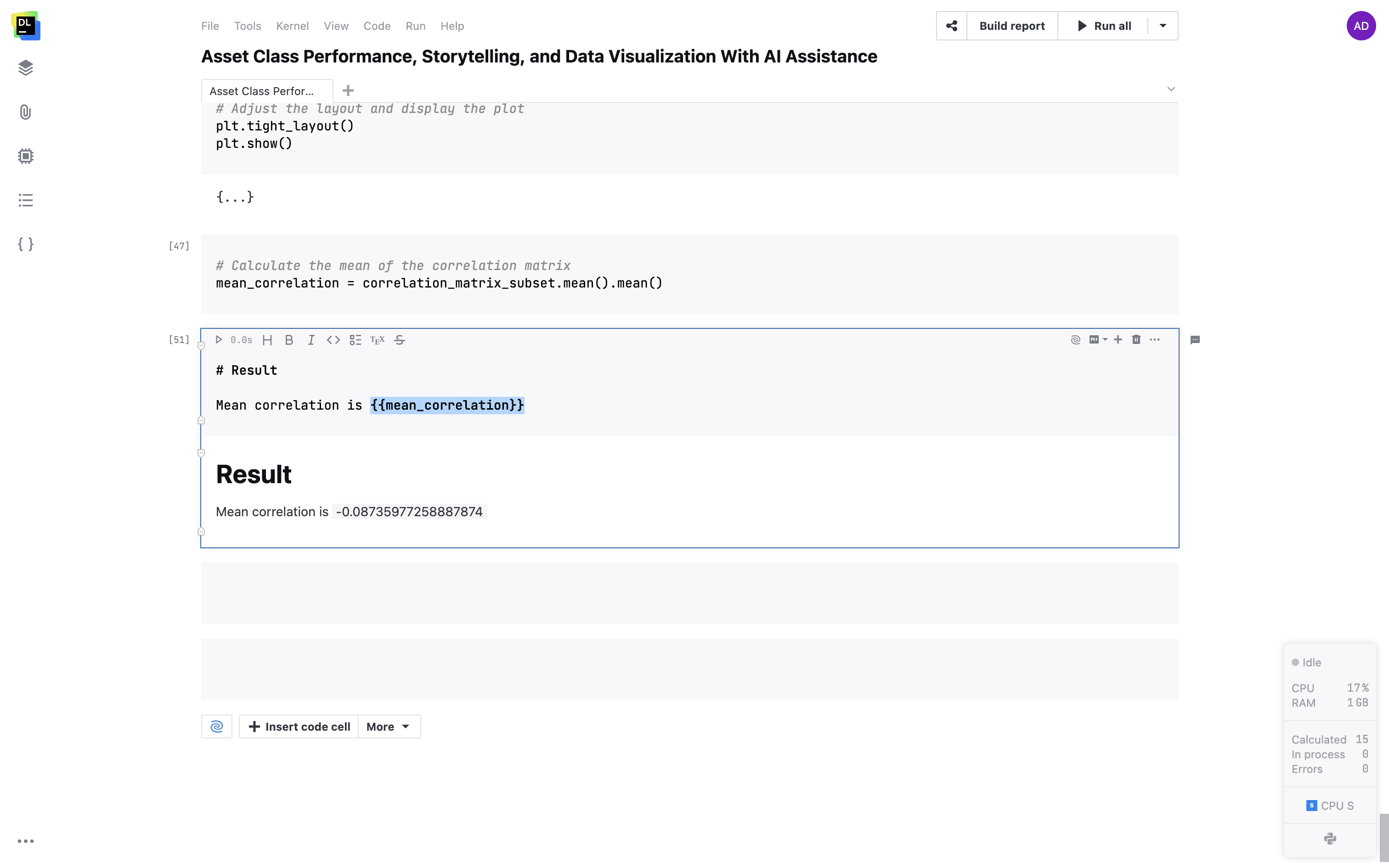
Suporte a variáveis em células Markdown
Incorpore suas variáveis em células Markdown com colchetes duplos. As variáveis serão convertidas dinamicamente em seus valores reais em seu texto.
Ambiente

Gerenciador de pacotes
O Datalore vem com um gerenciador de pacotes integrado que torna seu ambiente reproduzível. O gerenciador de pacotes permite que você instale e gerencie novos pacotes e garante que eles sejam persistidos quando você reabrir o notebook.
Ambientes de base personalizados
Crie vários ambientes de base a partir de imagens personalizadas do Docker. Você pode pré-configurar todas as dependências, versões de pacotes e configurações de ferramentas de compilação para que sua equipe não perca tempo instalando coisas manualmente e sincronizando as versões dos pacotes.
Pacotes de repositórios Git
Instale um pacote compatível com pip personalizado de um repositório Git anexando um branch Git ao seu notebook.
Scripts de inicialização
Configure um script que você deseja executar antes do início do notebook. Aqui, você pode especificar todas as ferramentas de compilação e dependências necessárias.
Visualizações
Aba Visualize
Obtenha alternativas de visualização automática dentro da aba Visualize para qualquer DataFrame pandas. Gráficos de pontos, linha, barra, área e de correlação ajudarão você a entender rapidamente o conteúdo dos seus dados. Se o conjunto de dados for grande, uma amostragem será computada automaticamente. Todos os gráficos podem então ser extraídos para células de código ou de gráfico para personalização posterior.
Suporte a todos os pacotes de visualização do Python
Crie visualizações com o pacote de sua escolha. Matplotlib, plotly, altair, seaborn, lets-plot e muitos outros pacotes são suportados pelos notebooks do Datalore.

Células de gráficos
Crie visualizações prontas para produção em apenas alguns cliques. O estado das células é compartilhado com os colaboradores, para que vocês possam trabalhar na visualização juntos.
Saídas interativas na forma de tabelas
Filtre e classifique dataframes do Pandas e resultados de consultas em SQL diretamente na saída das células. Selecione as colunas a serem mostradas, classifique o conjunto de dados por uma coluna específica, filtre com base em expressões "equals" e "contains", e salte facilmente para o início ou para o final do conjunto de dados. Depois de terminar de filtrar e classificar, use a opção Export to code cell para gerar o trecho de código do Pandas e tornar possível reproduzir a visualização da tabela.

Edite células DataFrame em tabelas interativas
Você não precisa mais baixar arquivos CSV para fazer um conjunto de edições em um DataFrame. Basta editar o conteúdo das células dentro das tabelas interativas e clicar em Export to code para reproduzir o resultado no notebook.

Estatísticas para DataFrames
Com apenas um clique, você pode obter estatísticas descritivas essenciais sobre uma DataFrame, dentro de uma aba Statistics separada. Para colunas categóricas, você verá a distribuição dos valores. Para colunas numéricas, o Datalore calculará os valores mínimo e máximo, a mediana, o desvio-padrão, os percentis e também realçará a porcentagem de zeros e outliers.

Controles interativos
Adicione controles interativos, tais como menus suspensos, controles deslizantes, campos de texto e células de data dentro dos seus notebooks e use os valores de entrada como variáveis dentro do seu código. Apresente as visualizações em células de gráficos e realce números específicos dentro de células de métrica.

Controle interativo do upload de arquivos
Agora os proprietários de relatórios e notebooks podem permitir que seus colaboradores façam o upload de arquivos em CSV, TXT ou de imagem a partir das suas máquinas locais. Defina os tipos de arquivos e os limites de tamanho para incorporar o upload de arquivos ao seu fluxo de trabalho de forma transparente.

Exporte para uma célula do banco de dados
Exporte DataFrames para tabelas existentes em um banco de dados diretamente do seu notebook. Personalize a exportação escolhendo o DataFrame, o banco de dados de destino, o esquema e a tabela. Você também pode aproveitar o recurso de agendamento e automatizar as exportações.

Suporte a IPyWidgets
O Datalore tem suporte a IPyWidgets, o framework clássico de widgets do Jupyter. Adicione controles interativos com código em Python, combine vários widgets em uma só saída de célula e use a seleção como uma variável nas partes seguintes do seu notebook.

Pré-visualização de arquivos em CSV
Abra arquivos em CSV e TSV a partir da aba de dados Attached, em uma aba separada dentro do editor do Datalore. Ordene os valores das colunas e divida o conteúdo do arquivo em páginas.

Edição de arquivos em CSV
Crie e edite arquivos em CSV e TSV diretamente de dentro do editor do Datalore. Você pode começar do zero e criar um arquivo novo ou editar o conteúdo de um arquivo já existente.

Terminal
Abra as janelas do Terminal dentro do editor, execute scripts .py e acesse o agente, o ambiente e o sistema de arquivos usando comandos bash padrão.

Visualizador de variáveis
Navegue pelas variáveis do notebook e pelos valores de parâmetros incorporados em um só lugar.

Controle de versão interno
Crie pontos de verificação de histórico personalizados que permitem reverter as alterações a qualquer momento usando a ferramenta de histórico. Ao navegar em um ponto de verificação, você verá a diferença entre a versão atual do notebook e aquela que está selecionada.

Computação
Execute notebooks em CPUs e GPUs
No Datalore, é possível executar notebooks em CPUs e GPUs. Você pode escolher a máquina necessária na UI. O tipo e a quantidade de recursos disponíveis dependem do plano que você possui. Encontre mais informações aqui.

Nuvem privada e máquinas no local
Você pode conectar qualquer tipo de hardware de servidor que já esteja usando ao Datalore e torná-lo acessível aos seus usuários através da interface do Datalore.
Modo reativo para pesquisa reproduzível
O modo reativo forçará a ordem de computação de cima para baixo e o recálculo automático das células abaixo da modificada. O estado do notebook será salvo após cada computação de célula e pode ser restaurado a qualquer momento.
Computação em segundo plano
Ative a computação em segundo plano para manter seu notebook em execução mesmo quando você fechar a aba do navegador. Você sempre terá acesso à sua lista de computações em execução no menu do usuário ou no painel do administrador.
Relatórios de uso da máquina
Baixe relatórios CSV que indicam quanto tempo que você gastou executando cada máquina, o que pode ajudar a entender em quais projetos você prestou mais atenção.
Agendamento de notebooks
Use o agendamento para executar seus notebooks por hora, diariamente, semanalmente ou mensalmente e forneça atualizações regulares para relatórios publicados. Escolha os parâmetros de agendamento na interface do usuário ou use a string CRON. Notifique os colaboradores do notebook sobre execuções bem-sucedidas ou com falha por e-mail.

Múltiplos agendamentos para notebooks
Especifique e gerencie vários agendamentos para um único notebook por meio da interface do usuário. Esse recurso permite que você crie agendamentos personalizados e execute seu notebook por hora, diariamente, semanalmente ou em datas específicas. Com a capacidade de configurar diferentes agendamentos com base nas suas necessidades exclusivas, você pode obter uma alocação de recursos mais eficiente e adaptar os tempos de execução do código às demandas do seu projeto.

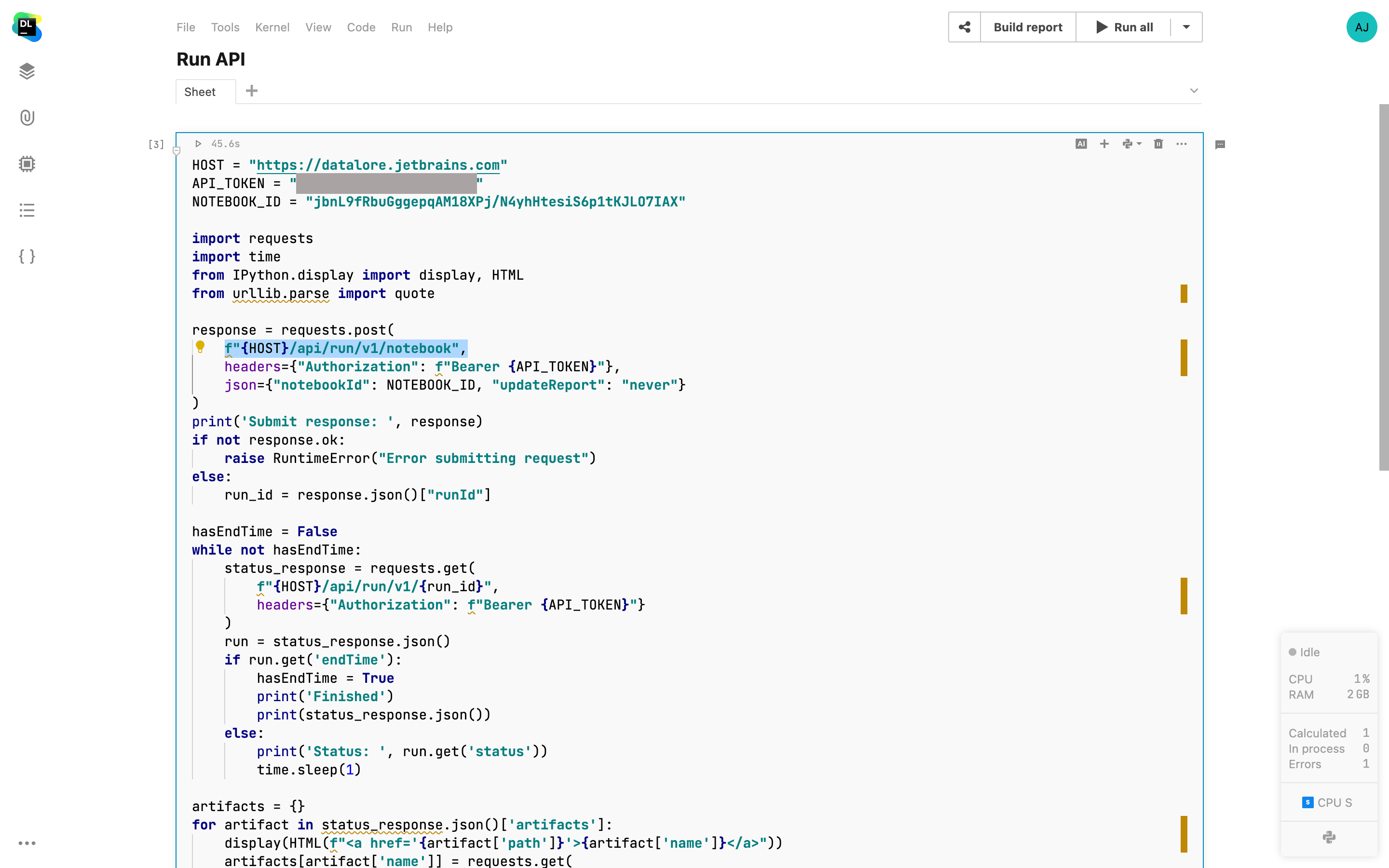
Datalore Run API
Agora, é possível acionar a execução de um notebook Datalore ou republicar um relatório com uma chamada de API. Esse recurso é um acréscimo às execuções programadas, que permitem acionar a reexecução de um notebook sob demanda a partir de aplicativos externos e notebooks internos do Datalore. Também é possível visualizar os resultados da execução no menu Scheduled run. Mais informações sobre como usar a API podem ser encontradas aqui.
Suporte nativo a pacotes do R
Em notebooks do R, agora você pode instalar pacotes de repositórios públicos e privados do R compatíveis com install.packages dentro da aba Environment manager. O uso do Environment manager ajuda a manter a mesma configuração de ambiente em todas as execuções do notebook. É possível configurar um repositório personalizado, criando um arquivo .Rprofile em init.sh ou uma imagem personalizada de um agente.
Embora a instalação do conda continue padrão na versão da nuvem, os clientes Enterprise podem configurar um ambiente-base personalizado sem o conda com o kernel do R. Isso levará a uma ausência de pacotes do conda nos resultados de pesquisas do Environment manager. Você pode encontrar um exemplo de tal instalação aqui.

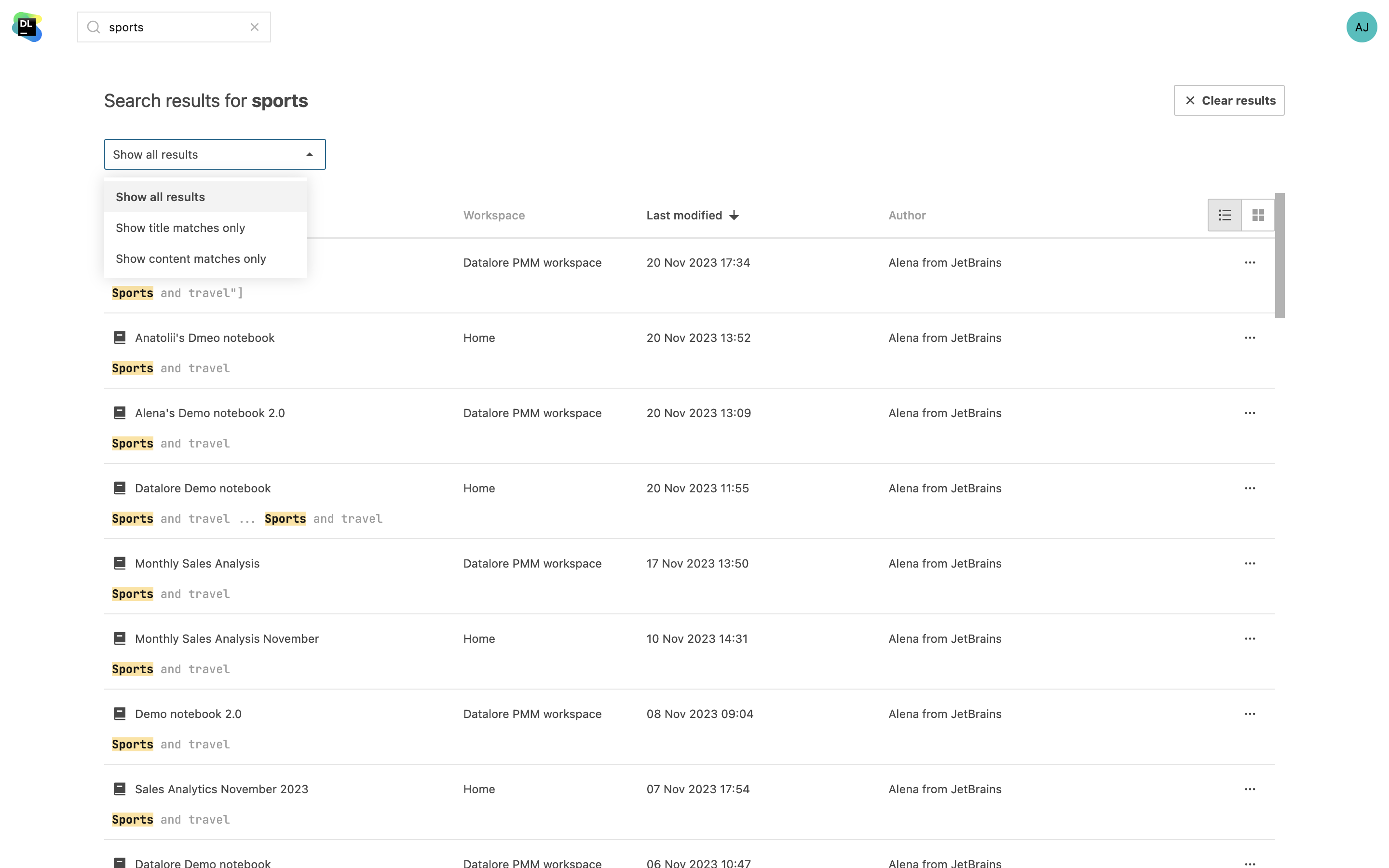
Pesquisa no conteúdo de notebooks
Localize seções específicas do código ou encontre as informações necessárias em todos os notebooks em todos os seus espaços de trabalho. Além de pesquisar pelos nomes dos notebooks, agora você também pode pesquisar pelos nomes das variáveis e pelo conteúdo. Você verá a sua pesquisa realçada nos resultados.