数据连接
无论您使用 CSV 文件、S3 存储桶还是 SQL 数据库,Datalore 都可以让您在一个 Notebook 中轻松访问和查询来自多个数据源的数据。
观看以下数据连接视频概览:
内部存储空间
Datalore 具有持久的内部存储空间,用于快速访问您的 Notebook 和其他工作工件。

Notebook 文件
无论您是上传本地文件和文件夹、通过链接导入数据,还是从代码中下载文件,所有数据都将存储在 Notebook 文件中。 与协作者共享 Notebook 时,将自动共享 Notebook 文件。

工作区文件
通过工作区文件在多个 Notebook 之间共享数据集。 在共享工作区中工作时,可以上传一次数据集,它将用于每个工作区编辑器。
从用户界面连接数据库
只需点击几下,即可直接从编辑器将您的 Notebook 连接到数据库,并使用原生 SQL 单元查询您的数据,无需将您的凭据传输到环境中。
Datalore 支持 Amazon Redshift、Azure SQL 数据库、MariaDB、MySQL、Oracle、PostgreSQL、Snowflake 等的用户和密码身份验证。 如果您有关于数据库连接的具体问题,请发送电子邮件至 datalore-support@jetbrains.com 与我们联系。

限制内省的数据库架构
在 Datalore 中创建数据库连接时,选择要内省的特定数据库架构和表。 这将有助于加快初始内省的速度,并使架构导航更容易。

自定义 JDBC 驱动程序支持
管理员现在可以添加自定义 JDBC 驱动程序,用于连接到 Datalore On-Premises 未原生支持的数据库。 Go to Admin panel | Miscellaneousand use the New custom database driver dialog to select and upload driver files from your local system.

SSH 隧道支持
在 Datalore 中使用 SSH 隧道连接到远程数据库。 这将在 Datalore 与网关服务器之间创建加密 SSH 连接。 通过 SSH 隧道连接可以连接到未暴露于公共网络的数据库。

S3 存储分区挂载
将 AWS S3 和 GCS 存储分区作为文件夹直接挂载到 Notebook,无需将您的凭据传输到环境中。

从代码中连接数据
除了通过用户界面连接支持的数据源外,您还可以像往常使用 Jupyter Notebook 一样,通过代码连接任何存储分区、数据库或数据存储空间。
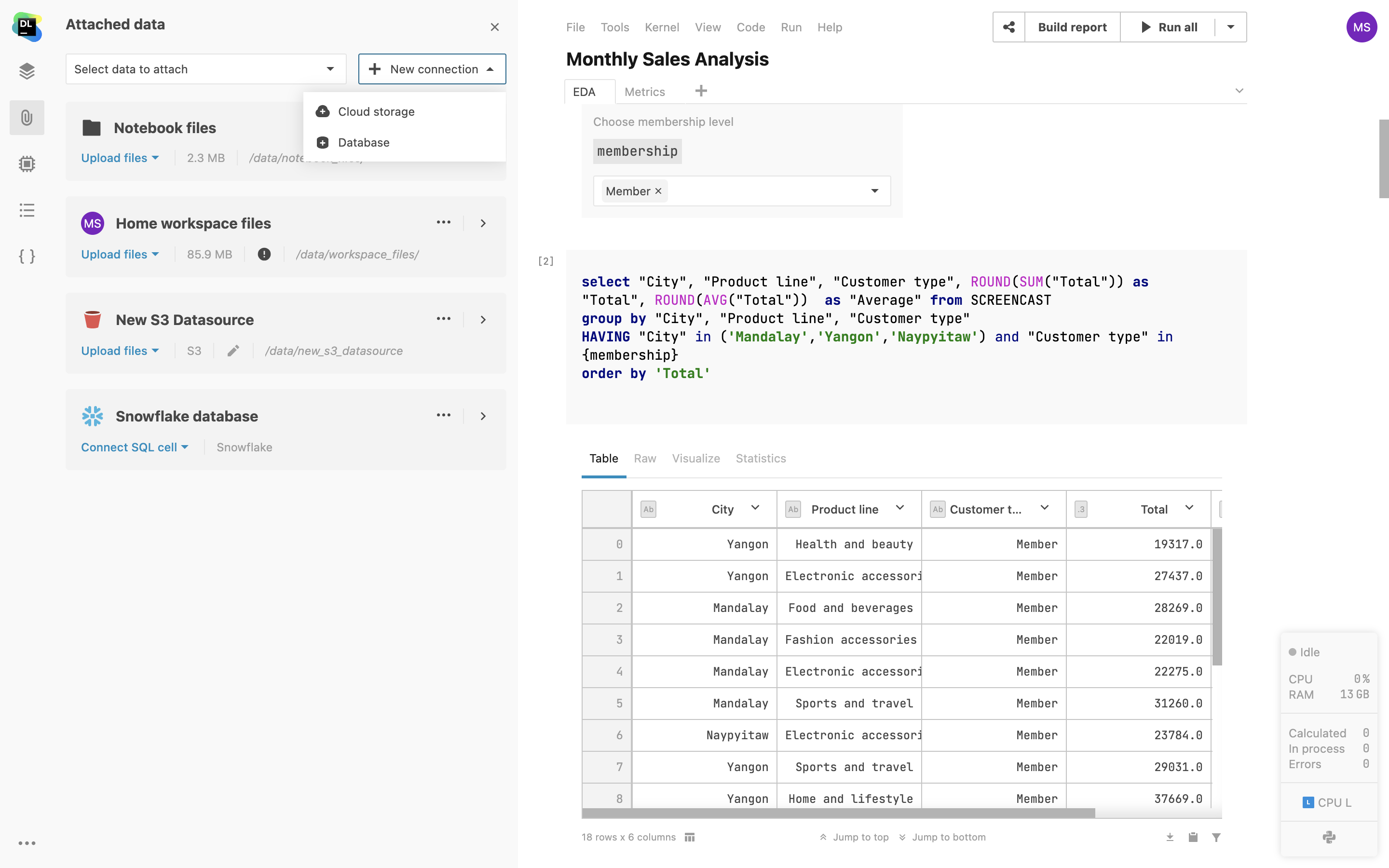
SQL 单元
添加原生 SQL 单元以查询您的数据库连接。 除了 SQL 语法高亮显示外,您还可以根据内省的数据库表获得代码补全。 查询结果会自动传输到 Pandas DataFrame,您可以继续在 Python 中处理数据集。

通过 SQL 单元查询 DataFrame
使用 SQL 单元可以从附加的文档轻松查询 2D DataFrame 和 CSV 文件,与使用数据库时相同。 只需浏览 Notebook 的 DataFrame,选择一个,然后将其用作 SQL 单元的源。 通过此功能,您可以使用 SQL 将不同源中的数据合并到单个 DataFrame 中,或将复杂查询分解为一系列 SQL 单元。

参数化 SQL 查询
在 Datalore 中,现在可以在 SQL 单元中使用 Python 代码中定义的变量(字符串、数字、布尔值、列表)。 这允许您使用参数化查询构建交互式报告,有助于减少编写的 SQL 代码,并为报告用户提供更好的 UI。

在隔离环境中使用数据库
借助此功能,即使在隔离环境中,您也可以使用数据库。 在没有互联网连接的情况下运行 SQL 代码,确保 Notebook 和数据库之间交换的信息保持准确一致,并最大限度地减少数据损坏或丢失的几率。
跨工作区克隆数据连接
您现在可以将数据库连接从一个工作区克隆到另一个工作区,消除了对重复设置的需求。 只需复制设置,不包括凭据,这样可以节省时间。 您还可以一次选择多个工作区。

SMB/CIFS 存储
通过 File system(文件系统)视图或直接从 Notebook 界面将 SMB/CIFS 存储添加到工作区。 在 Notebook 环境内即可访问和修改 SMB 文件夹内容。
