Notebook
任何数据科学项目的核心都是 Jupyter Notebook。 Datalore 提供了使用 Jupyter Notebook 的智能工具。 依靠其对 Python、SQL、R、Scala 和 Kotlin 的智能编码辅助,更快移动并更轻松地编写更高质量的代码。 Datalore 编辑器可以快速访问所有基本工具,包括附加的数据源、自动可视化、数据集统计、报告构建器、环境管理器、版本控制等。
观看以下视频,了解在 Datalore 中如何轻松创建 Jupyter Notebook:
与 Jupyter 兼容

Datalore 中的 Notebook 与 Jupyter 兼容,这意味着您可以上传现有 IPYNB 文件并继续在 Datalore 中处理它们。 此外,您还可以将 Notebook 导出为 IPYNB 文件。 请注意,将不导出数据连接和交互式控件。
Python Notebook

来自 PyCharm 的智能编码辅助
Datalore 与 PyCharm 的代码洞察功能捆绑在一起。 对于 Python Notebook,您可以获得一流的代码补全、形参信息、检查、快速修复和重构,帮助您轻松编写更优质的代码。

应用内文档
获得任何方法、函数、软件包或类的文档弹出窗口。 Datalore 将在您需要时向您展示文档。

Conda 和 pip 支持
Datalore 支持 pip 和 conda。 Pip 速度快,而且对所有人免费,conda 则仅可免费用于非商业用途。
Kotlin、Scala 和 R 笔记本
在 Datalore 中,您可以创建 Kotlin、Scala 和 R 笔记本。 您可以使用魔法命令安装软件包,在编写代码时,您将获得代码补全。

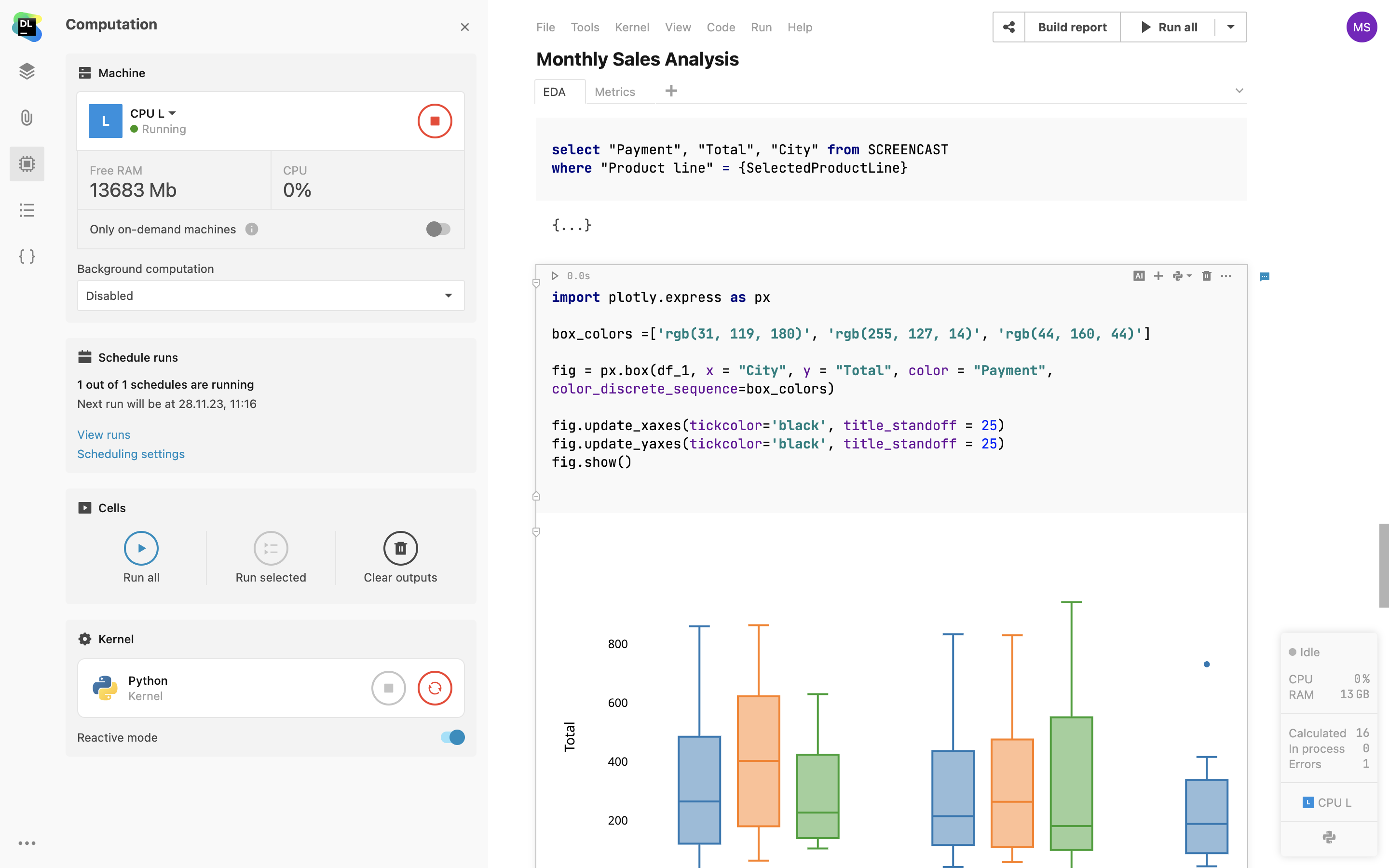
SQL 单元
添加原生 SQL 单元以查询您的数据库连接。 除了 SQL 语法高亮显示外,您还可以根据内省的数据库表获得代码补全。 查询结果会自动传输到 Pandas DataFrame,您可以继续在 Python 中处理数据集。

通过 SQL 单元查询 DataFrame
使用 SQL 单元可以从附加的文档轻松查询 2D DataFrame 和 CSV 文件,与使用数据库时相同。 只需浏览 Notebook 的 DataFrame,选择一个,然后将其用作 SQL 单元的源。 通过此功能,您可以使用 SQL 将不同源中的数据合并到单个 DataFrame 中,或将复杂查询分解为一系列 SQL 单元。

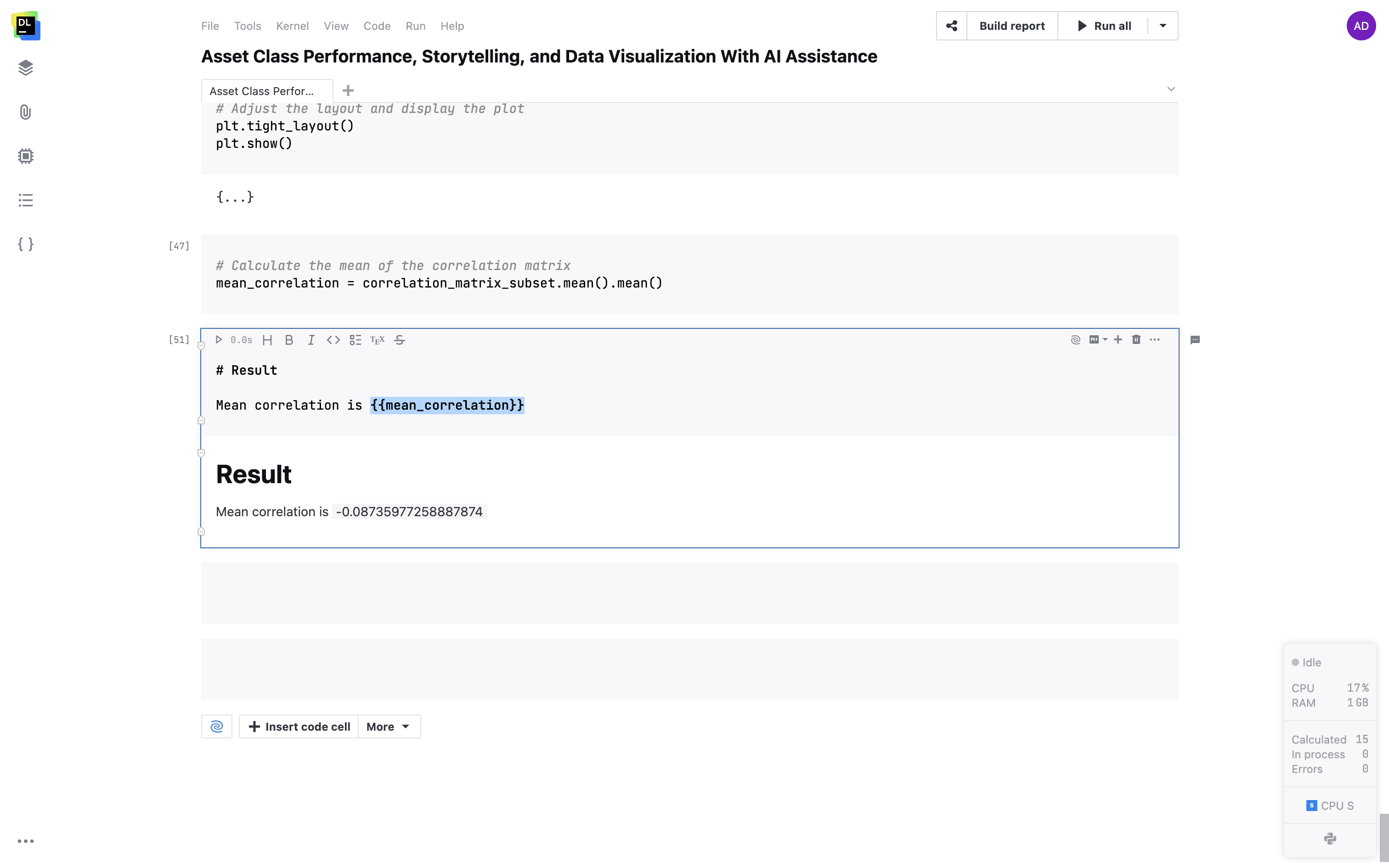
在 Markdown 单元中支持变量
在 Markdown 单元中使用双大括号嵌入您的变量。 变量将在您的文本中动态转换为实时值。
环境

软件包管理器
Datalore 附带一个集成软件包管理器,能够重现您的环境。 软件包管理器让您可以安装和管理新软件包,并确保在您重新打开 Notebook 时它们已进行预配置。
自定义基础环境
使用自定义 Docker 镜像创建多个基础环境。 您可以预先配置所有依赖项、软件包版本和构建工具配置,这样您的团队便不必花时间来执行手动安装和同步软件包版本。
来自 Git 仓库的软件包
通过将 Git 分支附加到您的 Notebook,从 Git 仓库安装与 pip 兼容的自定义软件包。
初始化脚本
配置要在 Notebook 启动之前运行的脚本。 在这里,您可以指定所有必要的构建工具和所需的依赖项。
可视化
Visualize(可视化)标签页
在 Visualize(可视化)标签页中获得任何 pandas DataFrame 的自动可视化选项。 点、线、条、面积和关联图将帮助您快速了解数据的内容。 如果数据集很大,将自动对其采样。 然后可以将所有图提取到代码或图表单元中进行进一步自定义。
支持所有 Python 可视化软件包
使用您选择的软件包创建可视化效果。 Datalore Notebook 中支持 Matplotlib、plotly、altair、seaborn、lets-plot 和许多其他软件包。

图表单元
只需点击几下即可创建可付诸生产的可视化效果。 单元的状态与协作者共享,因此您可以与他们共同处理可视化效果。
交互式表输出
直接在单元输出中对 Pandas DataFrame 和 SQL 查询结果应用筛选和排序。 选择要显示的列,按特定列排列数据集,根据“equals”和“contains”表达式进行筛选,并轻松跳转到数据集的顶部或底部。 完成筛选和排序后,使用 Export to code cell(导出到代码单元)选项生成 Pandas 代码段并使表视图可重现。

在交互式表中编辑 DataFrame 单元
您不再需要下载 CSV 文件在 DataFrame 中进行一组编辑。 在交互式表内编辑单元内容,然后点击 Export to code(导出到代码)即可在 Notebook 中重现结果。

DataFrame 统计信息
只需点击一下,您就可以在单独的 Statistics(统计信息)标签页中获得 DataFrame 的基本描述性统计信息。 对于分类列,您将看到值的分布,对于数值列,Datalore 将计算最小值、最大值、中值、标准差、百分位数,并高亮显示零值和异常值的百分比。

交互式控件
在 Notebook 中添加交互式输入,例如下拉菜单、滑块、文本输入和日期单元,并将输入值用作代码中的变量。 使用图表单元呈现可视化并高亮显示指标单元中的特定数字。

文件上传工具交互式控制
报告和 Notebook 所有者现在可以让协作者从本地计算机上传 CSV、TXT 或图像文件。 设置文件类型和大小限制,将文件上传无缝整合到工作流中。

Export to database(导出到数据库)单元
直接从 Notebook 将 DataFrame 导出到数据库中的现有表。 选择 DataFrame、目标数据库、架构和表来自定义导出。 此外,您还可以利用调度功能和自动执行导出。

IPyWidgets 支持
Datalore 支持经典 Jupyter 微件框架 IPyWidgets。 使用 Python 代码添加交互式控件,将多个微件组合到一个单元输出,并将选区用作 Notebook 以下部分中的变量。

CSV 文件预览
从 Datalore 编辑器内的单独标签页中的 Attached data(附加数据)标签页中打开 CSV 和 TSV 文件。 对列值进行排序并对文件内容进行分页。

CSV 文件编辑
直接在 Datalore 编辑器内部创建和编辑 CSV 和 TSV 文件。 您可以从头创建新文件,也可以编辑现有文件的内容。

终端
在编辑器中打开终端窗口,执行 .py 脚本,并使用标准 bash 命令访问代理、环境和文件系统。

变量查看器
从一个地方浏览笔记本变量和内置形参值。

内部版本控制
创建自定义历史记录检查点,让您随时可以使用历史记录工具恢复更改。 浏览检查点时,您将看到当前版本的 Notebook 与所选版本之间的区别。

计算
在 CPU 和 GPU 上运行笔记本
在 Datalore 中,您可以在 CPU 和 GPU 上执行您的 Notebook。 您可以从用户界面中选择所需的计算机。 您获得的资源类型和数量取决于您拥有的方案。 请在此处了解更多信息。

私有云和本地部署计算机
您可以将已在使用的任何类型的服务器硬件连接到 Datalore,并让用户能够从 Datalore 的界面进行访问。
反应式模式有助于实现可重现研究
反应式模式将强制执行自上而下的评估顺序并自动重新计算修改后的单元。 Notebook 状态将在每次单元评估后保存,并可随时恢复。
后台计算
打开后台计算,即使您关闭浏览器标签页,Notebook 也将保持运行。 您将始终可以从 User(用户)菜单或 Admin(管理员)面板中访问正在运行的计算列表。
计算机使用情况报告
下载包含您运行每台计算机所花费时间的 CSV 报告,这可能有助于您了解您最关注的项目。
Notebook 计划
计划您的 Notebook 每小时、每天、每周或每月运行一次,并将定期报告推送到已发布的报告。 从用户界面上选择计划参数或使用 CRON 字符串。 在运行成功或失败时通过电子邮件通知 Notebook 协作者。

多 Notebook 时间表
通过用户界面为单个 Notebook 指定和管理多个时间表。 这项功能可用于创建自定义时间表并每小时、每天、每周或在特定日期运行 Notebook。 按照独特需求设置不同的时间表,您可以实现更有效的资源分配并根据项目需求定制代码执行时间。

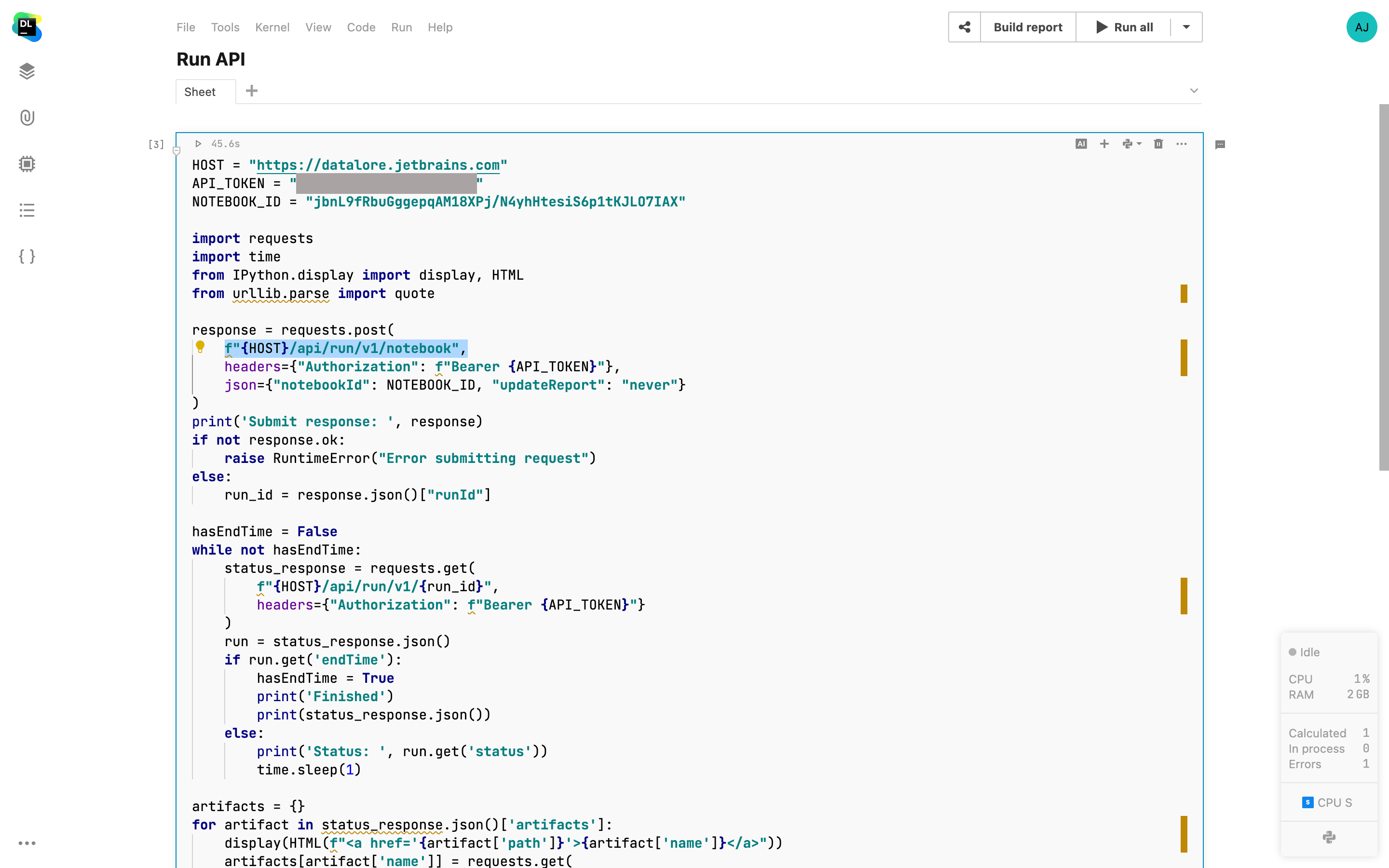
Datalore Run API
现在可以通过 API 调用来触发运行 Datalore Notebook 或重新发布报告。 此功能可以补充定时运行,允许您从外部应用和内部 Datalore Notebook 按需触发重新运行 Notebook。 也可以从 Scheduled run(定时运行)菜单中查看运行结果。 在此处详细了解如何使用 API 。
原生 R 软件包支持
对于 R Notebook,您现在可以在 Environment manager(环境管理器)标签页中安装 install.packages 支持的公共和私有 R 软件包仓库中的软件包。 使用环境管理器有助于在整个 Notebook 运行过程中保持环境配置的持久性。 自定义仓库可以通过在 init.sh 中创建 .Rprofile 文件或自定义代理镜像来配置。
虽然 conda 安装在云版本中仍为默认设置,但 Enterprise 客户可以使用 R 内核配置非 conda 自定义基础环境。 这将导致环境管理器搜索结果中缺少 conda 软件包。 您可以在这里找到此类安装的示例。

Notebook 内容搜索
在工作区的所有 Notebook 中找到特定代码部分或查找必要信息。 除了搜索 Notebook 名称外,您现在还可以搜索变量名称和内容。 您将在搜索结果中看到高亮显示的查询。