Notebooks
Das Herzstück eines jeden Data-Science-Projekts ist ein Jupyter-Notebook. Datalore bietet Ihnen intelligente Tools für die Arbeit mit Jupyter-Notebooks. Dank der intelligenten Programmierhilfen für Python, SQL, R, Scala und Kotlin kommen Sie schneller voran und schreiben mit weniger Aufwand besseren Code. Der Datalore-Editor bietet Ihnen einen einfachen Zugriff auf alle wichtigen Tools: angehängte Datenquellen, automatische Visualisierungen, Datensatz-Statistiken, Berichtserstellung, Umgebungsmanager, Versionierung und vieles mehr.
Im folgenden Video können Sie sehen, wie einfach sich Jupyter-Notebooks in Datalore erstellen lassen:
Jupyter-kompatibel

Die Notebooks in Datalore sind Jupyter-kompatibel, d. h. Sie können Ihre vorhandenen .ipynb-Dateien einfach hochladen und in Datalore mit ihnen weiterarbeiten. Umgekehrt haben Sie die Möglichkeit, Notebooks als .ipynb-Dateien zu exportieren. Beachten Sie dabei, dass Datenverbindungen und interaktive Steuerelemente nicht exportiert werden.
Python-Notebooks

Intelligente Programmierhilfen aus PyCharm
Datalore nutzt die Code-Insight-Funktionen von PyCharm. In Python-Notebooks können Sie dadurch eine erstklassige Code-Completion, Parameterinformationen, Inspektionen, Quick-Fixes und Refactorings nutzen, um mit weniger Aufwand besseren Code zu schreiben.

In-App-Dokumentation
Dokumentations-Popups für Methoden, Funktionen, Pakete und Klassen erleichtern Ihnen die Arbeit. Datalore zeigt Ihnen Dokumentationshinweise genau dort, wo Sie sie benötigen.

Conda- und pip-Unterstützung
Datalore unterstützt sowohl pip als auch conda. pip ist schnell und für alle kostenlos, während conda nur für den nichtkommerziellen Gebrauch kostenlos ist.
Kotlin-, Scala- und R-Notebooks
In Datalore können Sie Kotlin-, Scala- und R-Notebooks erstellen. Sie können mit Magic-Befehlen Pakete installieren und beim Programmieren die Code-Completion nutzen.

SQL-Zellen
Mit nativen SQL-Zellen können Sie Ihre Datenbankverbindungen abfragen. Außer der SQL-Syntaxhervorhebung steht Ihnen auch eine Code-Completion basierend auf der Introspektion der Datenbanktabellen zur Verfügung. Das Abfrageergebnis wird automatisch in einen Pandas-DataFrame übertragen und kann in Python weiterbearbeitet werden.

DataFrame-Abfragen über SQL-Zellen
Sie können SQL-Zellen verwenden, um 2D-DataFrames und CSV-Dateien aus angehängten Dokumenten genauso unkompliziert wie eine Datenbank abzufragen. Wählen Sie einfach einen DataFrame aus Ihrem Notebook aus und verwenden Sie ihn als Quelle für Ihre SQL-Zellen. Mit dieser Funktion können Sie per SQL die Daten verschiedener Quellen in einen einzigen DataFrame zusammenführen oder komplexe Abfragen in eine Abfolge von SQL-Zellen zerlegen.

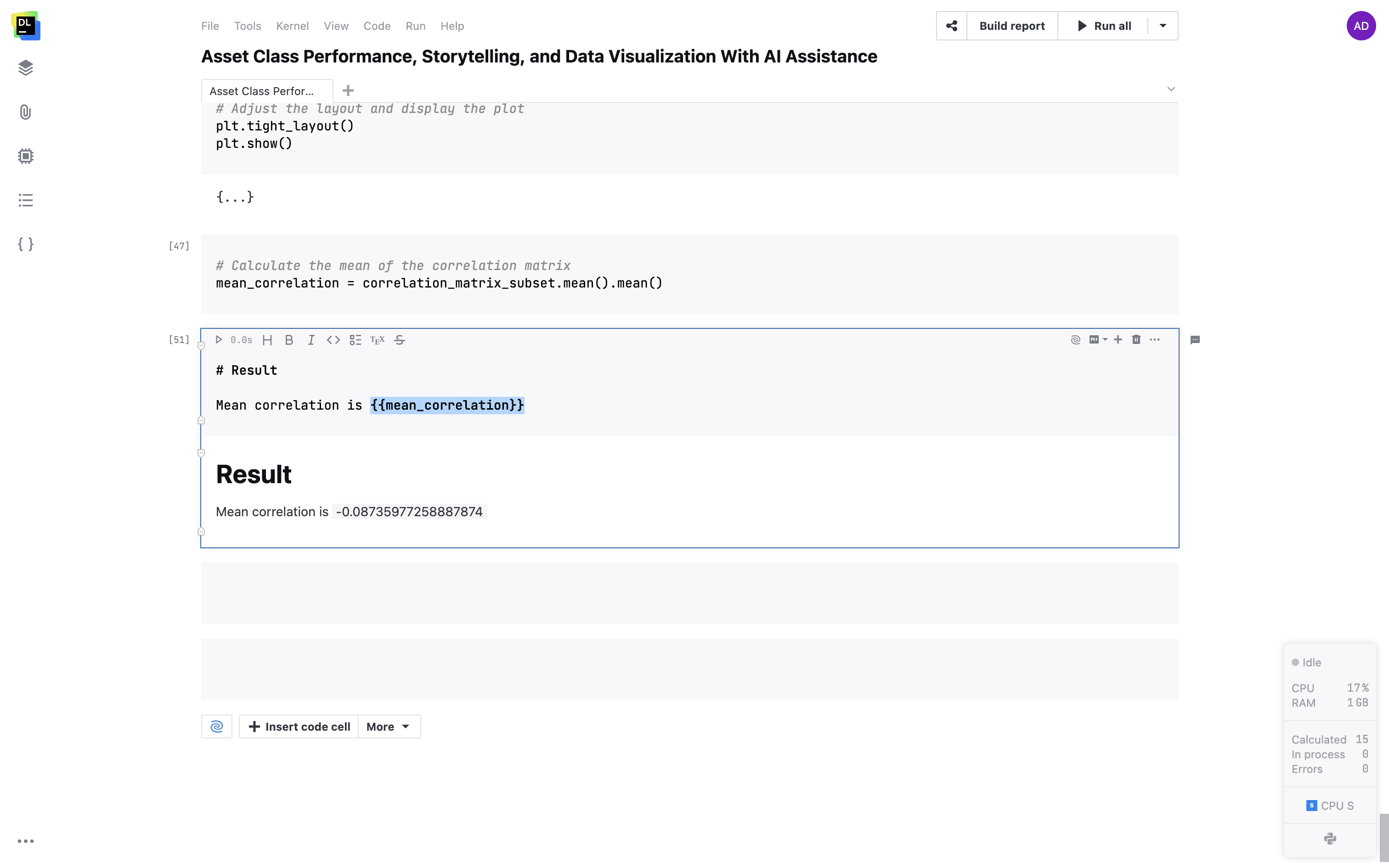
Unterstützung für Variablen in Markdown-Zellen
Mit doppelten geschweiften Klammern können Sie Ihre Variablen in Markdown-Zellen einbetten. In Ihrem Text werden dynamisch die jeweils aktuellen Werte der Variablen angezeigt.
Umgebung

Paket-Manager
Datalore enthält einen integrierten Paketmanager, mit dem Sie Ihre Umgebungen reproduzieren können. Der Paketmanager installiert und verwaltet neue Pakete und stellt sicher, dass diese auch beim erneuten Öffnen des Notebooks vorkonfiguriert sind.
Benutzerdefinierte Basisumgebungen
Sie können aus benutzerdefinierten Docker-Images unterschiedliche Basisumgebungen erstellen. Sie können alle Abhängigkeiten, Paketversionen und Buildtool-Einstellungen vorkonfigurieren, damit Ihr Team keine Zeit darauf verschwenden muss, Pakete manuell zu installieren und Paketversionen zu synchronisieren.
Pakete aus Git-Repositories
Sie können eigene pip-kompatible Pakete aus einem Git-Repository installieren, indem Sie einen Git-Branch mit Ihrem Notebook verbinden.
Initialisierungsskripte
Sie können ein Skript konfigurieren, das vor dem Start des Notebooks ausgeführt wird. Hier können Sie alle erforderlichen Build-Tools und Abhängigkeiten angeben.
Visualisierungen
Visualize-Tab
Der Visualize-Tab bietet automatische Visualisierungsoptionen für alle pandas-DataFrames. Punkt-, Linien-, Balken-, Flächen- und Korrelationsdiagramme ermöglichen einen einfachen Überblick über Ihre Daten. Bei zu großen Datenmengen erfolgt ein automatisches Sampling. Alle Diagramme können dann zur weiteren Anpassung in Code- oder Diagrammzellen extrahiert werden.
Unterstützung für alle Python-Visualisierungspakete
Nutzen Sie für Visualisierungen das Paket Ihrer Wahl. Datalore-Notebooks unterstützen Matplotlib, plotly, altair, seaborn, lets-plot und viele andere Pakete.

Diagrammzellen
Erstellen Sie mit wenigen Klicks produktionsreife Visualisierungen. Der Zelleninhalt wird mit Mitwirkenden geteilt, sodass Sie gemeinsam an der Visualisierung arbeiten können.
Interaktive Tabellenausgaben
Sie können Pandas-DataFrames und SQL-Abfrageergebnisse direkt im Ausgabebereich der Zellen filtern und sortieren. Wählen Sie die anzuzeigenden Spalten aus, sortieren Sie die Daten nach einer bestimmten Spalte, wenden Sie „Ist-gleich“- und „Enthält“-Filter an und navigieren Sie unkompliziert an den Anfang oder das Ende des Datensatzes. Nach abgeschlossener Filterung und Sortierung lässt sich mit der Option Export to code cell ein Pandas-Code-Snippet generieren, das die Tabellenansicht reproduziert.

DataFrame-Zellen in interaktiven Tabellen bearbeiten
Sie müssen keine CSV-Dateien mehr herunterladen, um Änderungen in einem DataFrame vorzunehmen. Sie können den Inhalt von Zellen unkompliziert in interaktiven Tabellen bearbeiten und das Ergebnis mit einem Klick auf Export to code im Notebook reproduzieren.

DataFrame-Statistiken
Mit nur einem Klick können Sie sich die wichtigsten deskriptiven Statistiken für einen DataFrame in einem separaten Statistik-Tab anzeigen lassen. Bei Kategoriespalten sehen Sie die Verteilung der Werte, und bei numerischen Spalten berechnet Datalore Minimalwert, Maximalwert, Median, Standardabweichung und Perzentile und zeigt darüber hinaus den prozentualen Anteil von Null- und Ausreißerwerten an.

Interaktive Steuerelemente
Statten Sie Ihre Notebooks mit interaktiven Eingabeelementen wie Dropdown-Menüs, Schiebereglern, Textabfragen oder Datumszellen aus und speichern Sie die Eingabewerte in Variablen. Visualisieren Sie Ihre Daten in Diagrammzellen und heben Sie Zahlenwerte mittels Zahlenzellen hervor.

Interaktives Dateiupload-Steuerelement
Besitzer*innen von Berichten und Notebooks können jetzt ihren Mitwirkenden die Möglichkeit geben, CSV-, TXT- oder Bilddateien von ihren lokalen Systemen hochzuladen. Sie können Dateityp- und Größenbeschränkungen festlegen, um den Dateiupload nahtlos in Ihren Workflow einzubinden.

In Datenbank exportieren
Exportieren Sie DataFrames direkt aus Ihrem Notebook in vorhandene Tabellen einer Datenbank. Sie können den Export anpassen, indem Sie den DataFrame, die Zieldatenbank, das Schema und die Tabelle auswählen. Mithilfe der Zeitplanung können Sie die Exporte sogar automatisieren.

IPyWidgets-Unterstützung
Datalore unterstützt das klassische Jupyter-Widgets-Framework IPyWidgets. Sie können interaktive Steuerelemente mit Python-Code erstellen, mehrere Widgets in einer Zellenausgabe kombinieren und die ausgewählten Werte als Variablen in den nachfolgenden Teilen Ihres Notebooks verwenden.

Vorschau auf CSV-Dateien
Vom Tab „Attached data“ des Datalore-Editors aus können Sie CSV- und TSV-Dateien in einem separaten Tab öffnen. Die Spaltenwerte können sortiert und die Dateiinhalte seitenweise angezeigt werden.

Bearbeitung von CSV-Dateien
CSV- und TSV-Dateien lassen sich direkt im Datalore-Editor erstellen und bearbeiten. Sie können eine neue, leere Datei anlegen oder den Inhalt einer bestehenden Datei bearbeiten.

Terminal
Öffnen Sie Terminalfenster im Editor, führen Sie .py-Skripte aus und greifen Sie mit Bash-Standardbefehlen auf den Agent, die Umgebung und das Dateisystem zu.

Variablenansicht
Überprüfen Sie die Werte von Notebook-Variablen und integrierten Parametern an einem Ort.

Interne Versionierung
Erstellen Sie benutzerdefinierte Prüfpunkte, um Ihre Änderungen jederzeit im Verlaufstool rückgängig machen zu können. Wenn Sie einen Prüfpunkt auswählen, werden die Unterschiede zur aktuellen Notebookversion angezeigt.

Berechnungen
Notebook-Ausführung auf CPUs und GPUs
In Datalore können Sie Ihre Notebooks auf CPUs und GPUs ausführen. Sie können das benötigte System über die Bedienoberfläche auswählen. Die Art und Menge der verfügbaren Ressourcen hängt von Ihrem Abonnement ab. Nähere Informationen finden Sie hier.

In privaten Clouds installierte oder lokale Systeme
Sie können jede Art von bestehender Server-Hardware mit Datalore verbinden und über die Datalore-Bedienoberfläche Ihrem Team zugänglich machen.
Reaktiver Modus für reproduzierbare Forschungsergebnisse
Der reaktive Modus erzwingt eine Auswertung von oben nach unten sowie die automatische Neuberechnung von Zellen, die sich unterhalb einer geänderten Zelle befinden. Der Notebook-Zustand wird nach jeder Zellenauswertung gespeichert und kann jederzeit wiederhergestellt werden.
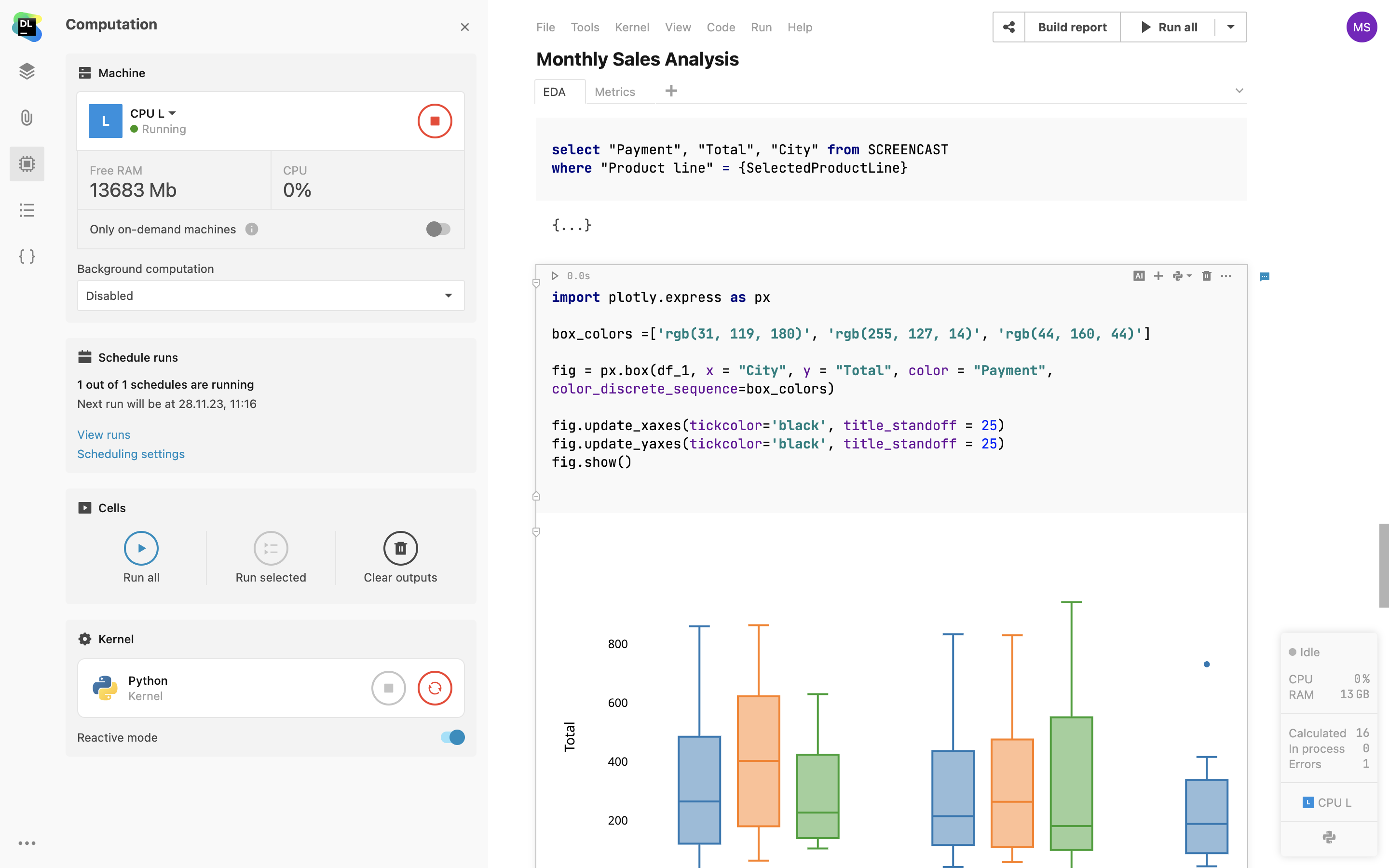
Berechnungen im Hintergrund
Aktivieren Sie die Hintergrundberechnung, um Ihr Notebook auch nach dem Schließen des Browser-Tabs weiter auszuführen. Ihre laufenden Berechnungen sind jederzeit über das Benutzermenü oder das Admin-Panel zugänglich.
Berichte zur Systemnutzung
Laden Sie CSV-Berichte herunter, in denen die Ausführungszeiten jedes Systems aufgeführt sind – so können Sie ermitteln, welchen Projekten Sie die meisten Ressourcen zugeteilt haben.
Zeitgesteuerte Notebook-Ausführung
Nutzen Sie die Zeitplanung, um Ihre Notebooks stündlich, täglich, wöchentlich oder monatlich auszuführen und regelmäßig aktualisierte Berichte zu veröffentlichen. Sie können die Zeitplan-Einstellungen über die Bedienoberfläche vornehmen oder einen CRON-String verwenden. Notebook-Mitwirkende können bei erfolgreichen oder fehlgeschlagenen Ausführungen per E-Mail benachrichtigt werden.

Mehrere Zeitpläne für Notebooks
Sie können in der Bedienoberfläche mehrere Zeitpläne für ein Notebook anlegen und verwalten. Mit dieser Funktion können Sie individuelle Zeitpläne erstellen und Ihr Notebook stündlich, täglich, wöchentlich oder an bestimmten Tagen ausführen. Die Option, unterschiedliche Zeitpläne gemäß Ihren individuellen Anforderungen einzurichten, ermöglicht eine effizientere Ressourcenzuweisung und die Anpassung der Codeausführung an die Anforderungen Ihres Projekts.

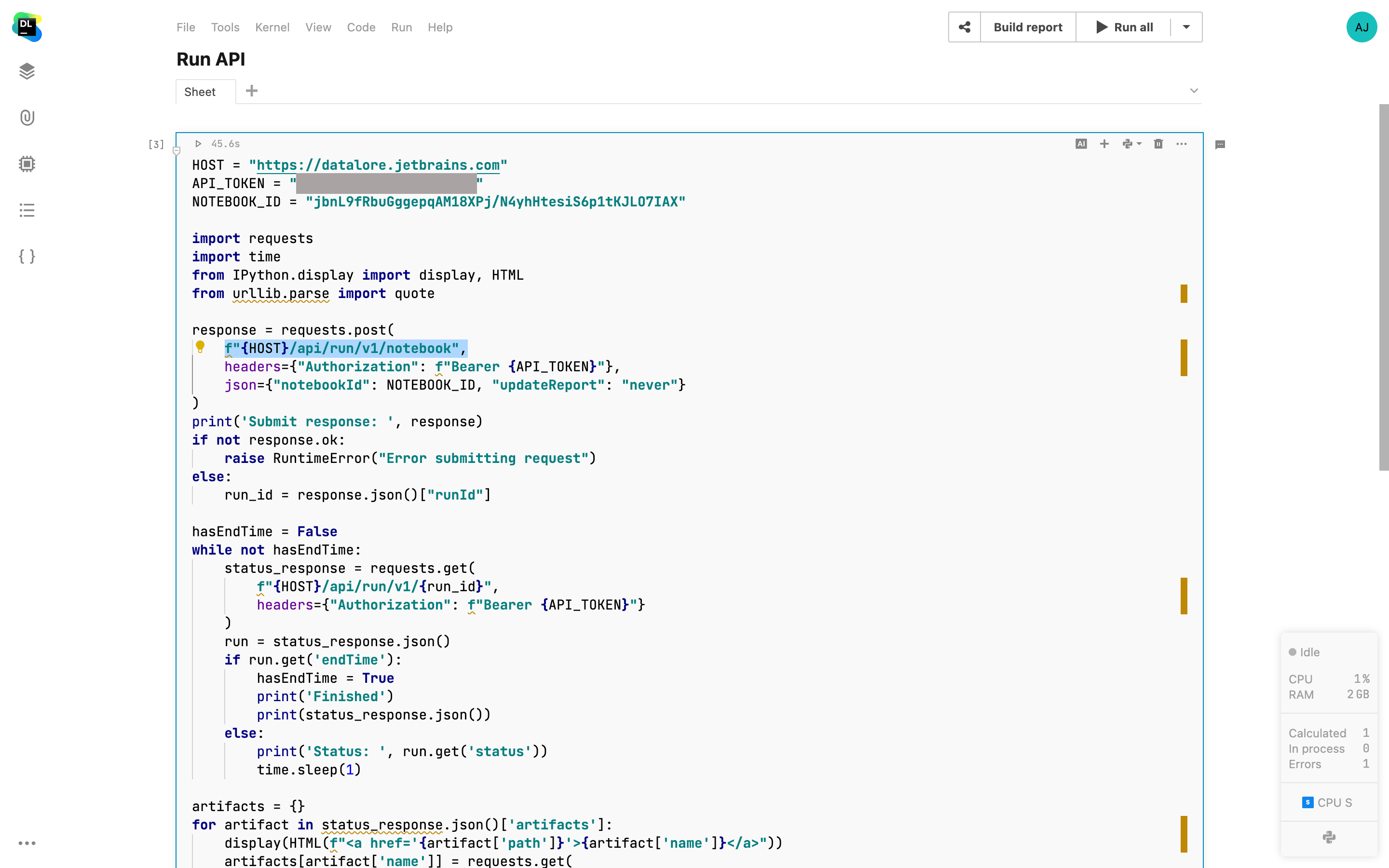
Datalore-Run-API
Es ist jetzt möglich, die Ausführung eines Datalore-Notebooks oder die Neuveröffentlichung eines Berichts mit einem API-Aufruf auszulösen. Diese Funktion ist eine Ergänzung zu den geplanten Runs, die es Ihnen ermöglicht, die erneute Ausführung eines Notebooks bei Bedarf von externen Anwendungen und internen Datalore-Notebooks aus anzustoßen. Es ist auch möglich, die Ergebnisse des Runs über das Menü Scheduled run anzuzeigen. Weitere Informationen zur Verwendung der API finden Sie hier.
Unterstützung für native R-Pakete
Für R-Notebooks können Sie jetzt dank der Unterstützung durch install.packages auf dem Tab Environment Manager Pakete aus öffentlichen und privaten R-Paket-Repositories installieren. Durch die Verwendung des Environment Manager können Sie Ihre Umgebungskonfiguration über mehrere Notebook-Läufe hinweg konstant halten. Sie können ein benutzerdefiniertes Repository konfigurieren, indem Sie eine .Rprofile-Datei in init.sh oder ein benutzerdefiniertes Agent-Image erstellen.
Die conda-Installation ist in der Cloud-Version zwar weiterhin die Standardeinstellung, Enterprise-Kunden können jedoch eine andere Basisumgebung mit dem R-Kernel konfigurieren. Als Folge werden in den Suchergebnissen des Environment Manager keine conda-Pakete angezeigt. Ein Beispiel für eine solche Installation finden Sie hier.

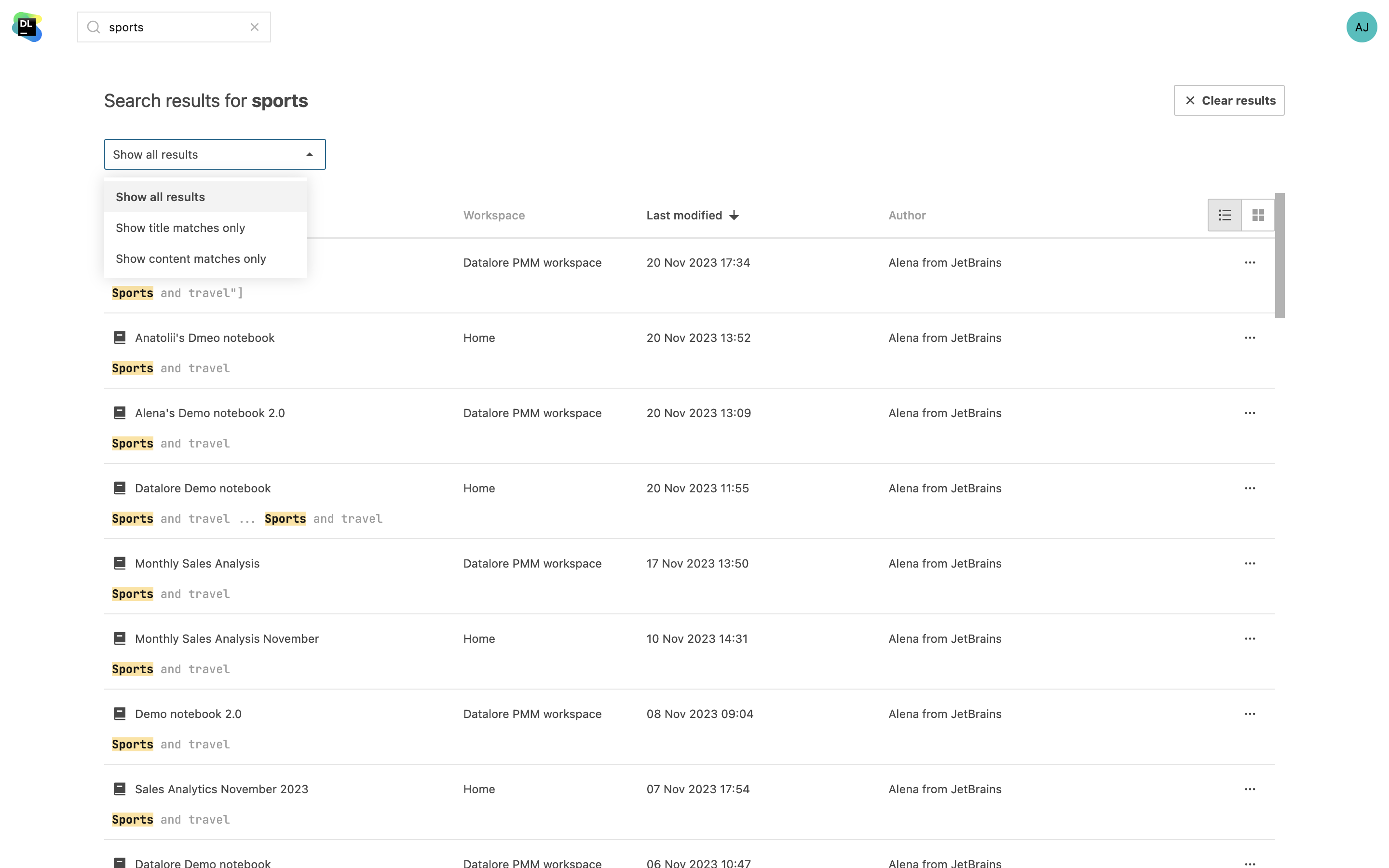
Suche in Notebook-Inhalten
Sie können jetzt in allen Notebooks in Ihrem Workspace bestimmte Codeabschnitte oder benötigte Informationen finden. Neben Notebook-Namen können Sie jetzt auch nach Variablennamen und Inhalten suchen. Ihre Suchbegriffe werden in den Ergebnissen hervorgehoben.