ノートブック
Jupyter ノートブックはあらゆるデータサイエンスプロジェクトで中心的な役割を果たしています。 Datalore には Jupyter ノートブックを操作するためのスマートなツールが備わっています。 Python、SQL、R、Scala、および Kotlin のスマートコーディング支援を利用することで、より迅速に作業を進め、より少ない労力で高品質のコードを記述することができます。 Datalore エディターでは、接続済みのデータソース、自動可視化、データセットの統計、レポートビルダー、環境マネージャー、バージョン管理など、すべての基本ツールに素早くアクセスできます。
Datalore での Jupyter ノートブック作成がどれほど簡単かを以下の動画でご覧ください。
Jupyter 対応

Datalore のノートブックは Jupyter 対応であるため、既存の IPYNB ファイルを Datalore にアップロードして、そのまま作業を続けることができます。 さらに、ノートブックを IPYNB ファイルとしてエクスポートすることも可能です。 データ接続と対話型コントロールはエクスポートされないことにご注意ください。
Python ノートブック

PyCharm のスマートなコーディング支援
Datalore には PyCharm 由来のコードインサイト機能が搭載されています。 Python ノートブックに対応した最高クラスのコード補完、パラメーター情報、インスペクション、クイックフィックス、およびリファクタリングを使用できるため、少ない労力で質の高いコードを書けます。

アプリ内ドキュメント
メソッド、関数、パッケージ、またはクラスに関するドキュメントをポップアップ表示できます。 Datalore では必要な場所にドキュメントを表示できます。

Conda と pip のサポート
Datalore は pip と Conda の両方をサポートしています。 pip は高速で誰でも無料で使用できますが、Conda は非商用利用に限り無料です。
Kotlin、Scala、および R ノートブック
Datalore では、Kotlin、Scala、および R ノートブックを作成できます。 パッケージのインストールにはマジックコマンドを使用でき、コードを記述する際にはコード補完を使用できます。

SQL セル
ネイティブ SQL セルを追加して、データベースに接続してクエリを実行できます。 SQL の構文ハイライト機能のほかに、イントロスペクションを行なったデータベーステーブルに基づくコード補完機能も使用できます。 クエリ結果は自動的に pandas DataFrame に転送されるため、Python でデータセットの操作を続行できます。

SQL セルを使用した DataFrame へのクエリ実行
データベースと同様に、SQL セルを使用して添付ドキュメントから簡単に 2D DataFrame と CSV ファイルにクエリを実行できます。 ノートブックの DataFrame を参照し、選択したものを SQL セルのソースとして使用するだけです。 この機能により、SQL を使用して複数の異なるソースのデータを単一の DataFrame にマージしたり、複雑なクエリを一連の SQL セルに分解したりできます。

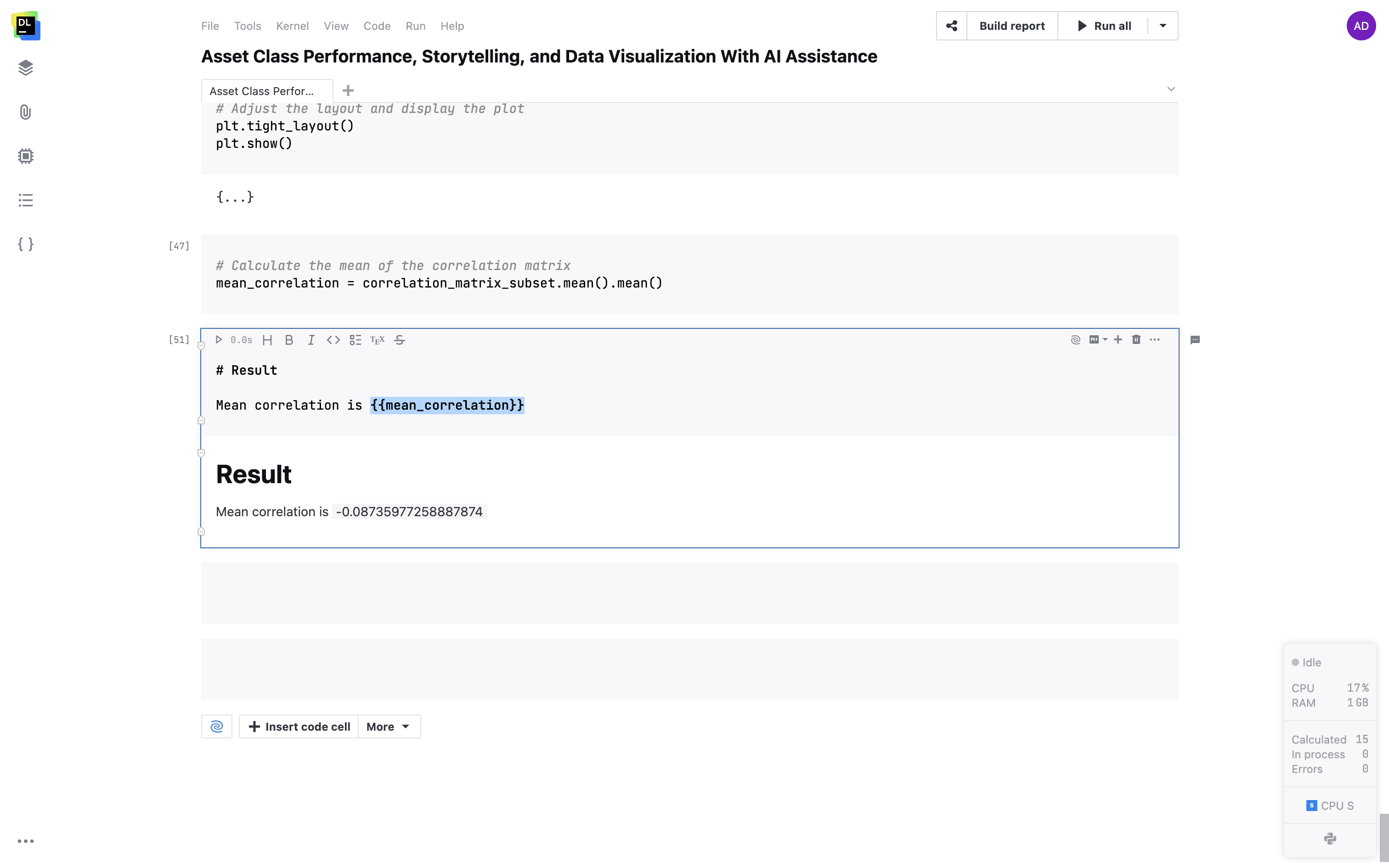
Markdown セルの変数のサポート
二重波括弧を使用して Markdown セルに変数を埋め込めます。 変数はテキスト内で実際の値に動的に変換されます。
環境

パッケージマネージャー
Datalore には環境を再現可能にするパッケージマネージャーが組み込まれています。 パッケージマネージャーを使用することで、新しいパッケージのインストールと管理を行えるほか、ノートブックを開き直した際に常にパッケージを構成済みの状態にできます。
カスタムのベース環境
カスタム Docker イメージから複数のベース環境を作成できます。 すべての依存関係、パッケージバージョン、およびビルドツール構成をあらかじめ構成しておくことができるため、チームは手動インストールやパッケージバージョンの同期に時間をかける必要がありません。
Git リポジトリのパッケージ
ノートブックに Git ブランチを関連付けることで、Git リポジトリからカスタム pip 対応パッケージをインストールできます。
初期化スクリプト
ノートブックが起動する前に実行するスクリプトを構成できます。 その場合、必要となるすべてのビルドツールと依存関係を指定できます。
可視化
Visualize タブ
Visualize タブには pandas DataFrame の自動可視化オプションがあります。 Point、Line、Bar、Area、および Correlation の各プロットを使用して、データの内容を素早く理解することができます。 データセットが大きい場合は、自動的にサンプリングされます。 すべてのプロットはコードまたはチャートセルに抽出されるため、さらなるカスタマイズが可能です。
あらゆる Python 可視化パッケージをサポート
お好みのパッケージで可視化表現を作成できます。 Datalore ノートブックでは、Matplotlib、plotly、altair、seaborn、lets-plot など数多くのパッケージがサポートされています。

チャートセル
わずか数クリックで、本番対応の可視化表現を作成できます。 セルの状態はほかの共同作業ユーザーにも共有されるため、共同で可視化に取り組むことができます。
対話型テーブル出力
セル出力で直接 Pandas DataFrames と SQL クエリ結果のフィルタリングと並べ替えを行えます。 表示する列を選択し、特定の列でデータセットを並べ替え、「equals」および「contains」式に基づいてフィルタリングし、データセットの上部または下部へ簡単に移動できます。 フィルタリングと並べ替えを完了したら、Export to code cell(コードセルにエクスポート)オプションを使って Pandas コードスニペットを生成し、テーブルビューを複製可能にすることができます。

対話型テーブルでの DataFrame セルの編集
DataFrame で一連の編集を行う際に CSV ファイルをダウンロードする必要がなくなりました。 対話型テーブル内にあるセルの内容を編集して Export to code(コードにエクスポート)をクリックするだけで、ノートブック内に結果が再現されます。

DataFrame の統計
ワンクリックで独立した Statistics(統計)タブ内に DataFrame の説明的な基本統計情報が表示されます。 カテゴリ列には値の分布が表示され、数値列では Datalore によって最小値、最大値、中央値、標準偏差、パーセンタイルが計算され、ゼロと外れ値がハイライト表示されます。

対話型コントロール
ドロップダウン、スライダー、テキスト入力、日付セルなどの対話型入力をノートブックに追加し、入力値をコード内で変数として使用できます。 チャートのセルを使って可視化データを作成し、メトリクスセル内の特定の数字をハイライト表示できます。

ファイルアップローダーの対話型コントロール
レポートとノートブックのオーナーがコラボレーターにローカルマシンの CSV、TXT、または画像ファイルのアップロードを許可できるようになりました。 ファイルタイプとサイズの制限を設定し、ファイルアップロード機能をシームレスにワークフローに組み込めます。

データベースセルへのエクスポート
ノードブックからデータベースの既存テーブルに DataFrame を直接エクスポートできます。 DataFrame、ターゲットデータベース、スキーマ、テーブルを選択することで、エクスポートをカスタマイズできます。 スケジュール機能を利用してエクスポートを自動化することも可能です。

IPyWidgets のサポート
Datalore は古典的な Jupyter ウィジェットフレームワークである IPyWidgets をサポートしています。 Python コードで対話型コントロールを追加し、複数のウィジェットを 1 つのセル出力にまとめ、選択範囲をノートブック内の後続部分で変数として使用できます。

CSV ファイルのプレビュー
Attached data(添付データ)タブの CSV と TSV ファイルは、Datalore エディター内の独立したタブで開きます。 列の値を並べ替えたり、ファイルの内容を複数のページに分割して表示したりできます。

CSV ファイルの編集
Datalore エディター内で直接 CSV ファイルと TSV ファイルを作成したり、編集したりできます。 ファイルを新規作成するか、既存ファイルの内容を編集できます。

ターミナル
エディター内にターミナルウィンドウを開いて .py スクリプトを実行し、標準的な Bash コマンドを使ってエージェント、環境、およびファイルシステムにアクセスできます。

変数ビューアー
1 箇所でノートブックの変数や組み込みパラメーターの値を閲覧できます。

内部バージョン管理
カスタム履歴チェックポイントを作成すると、履歴ツールを使用していつでも変更を元に戻すことができます。 チェックポイントを参照する際は、ノートブックの現在のバージョンと選択したバージョンの差分を確認できます。

計算
CPU と GPU でのノートブックの実行
Datalore では、ノートブックを CPU と GPU で実行できます。 必要なマシンは UI から選択可能です。 取得するリソースのタイプと数は、ご利用のプランによって異なります。 詳細はこちらをご覧ください。

プライベートクラウドとオンプレミスのマシン
すでに使用している任意の種類のサーバーハードウェアを Datalore に接続し、ユーザーに Datalore のインターフェースからそのサーバーハードウェアへアクセスさせることができます。
Reactive モードによる再現性のある研究
Reactive モードでは、上から下への評価および変更されたセルの下にあるセルの自動再計算が実施されます。 ノートブックの状態はセルが評価されるたびに保存され、いつでも復元できます。
バックグラウンド計算
バックグラウンド計算をオンにすると、ブラウザーのタブを閉じてもノートブックを実行し続けることができます。 実行中の計算のリストには、User メニューまたは Admin パネルからいつでもアクセス可能です。
マシン使用率レポート
各マシンの実行時間を含む CSV レポートをダウンロードできます。どのプロジェクトに最も多く時間を費やしたかを理解するのに役立ちます。
ノートブックのスケジュール設定
スケジュール設定を使用して、ノートブックを毎時間、毎日、毎週、または毎月の単位で実行し、公開済みのレポートに定期的なアップデートを配信します。 ユーザーインターフェースからスケジュールパラメーターを選択するか、CRON 文字列を使用します。 実行が成功または失敗した時点でノートブックの共同作業者にメール通知を送信可能です。

複数のノートブックスケジュール
単一のノートブックに対する複数のスケジュールの指定と管理をユーザーインターフェースを使って行えます。 この機能ではカスタムスケジュールの作成に加えて、毎時、毎日、毎週、または特定の日付でのノートブックの実行が可能です。 個々のニーズに応じて異なるスケジュールをセットアップできるため、リソースをより効率的に割り当て、プロジェクトの要求に合わせてコード実行のタイミングを調整できます。

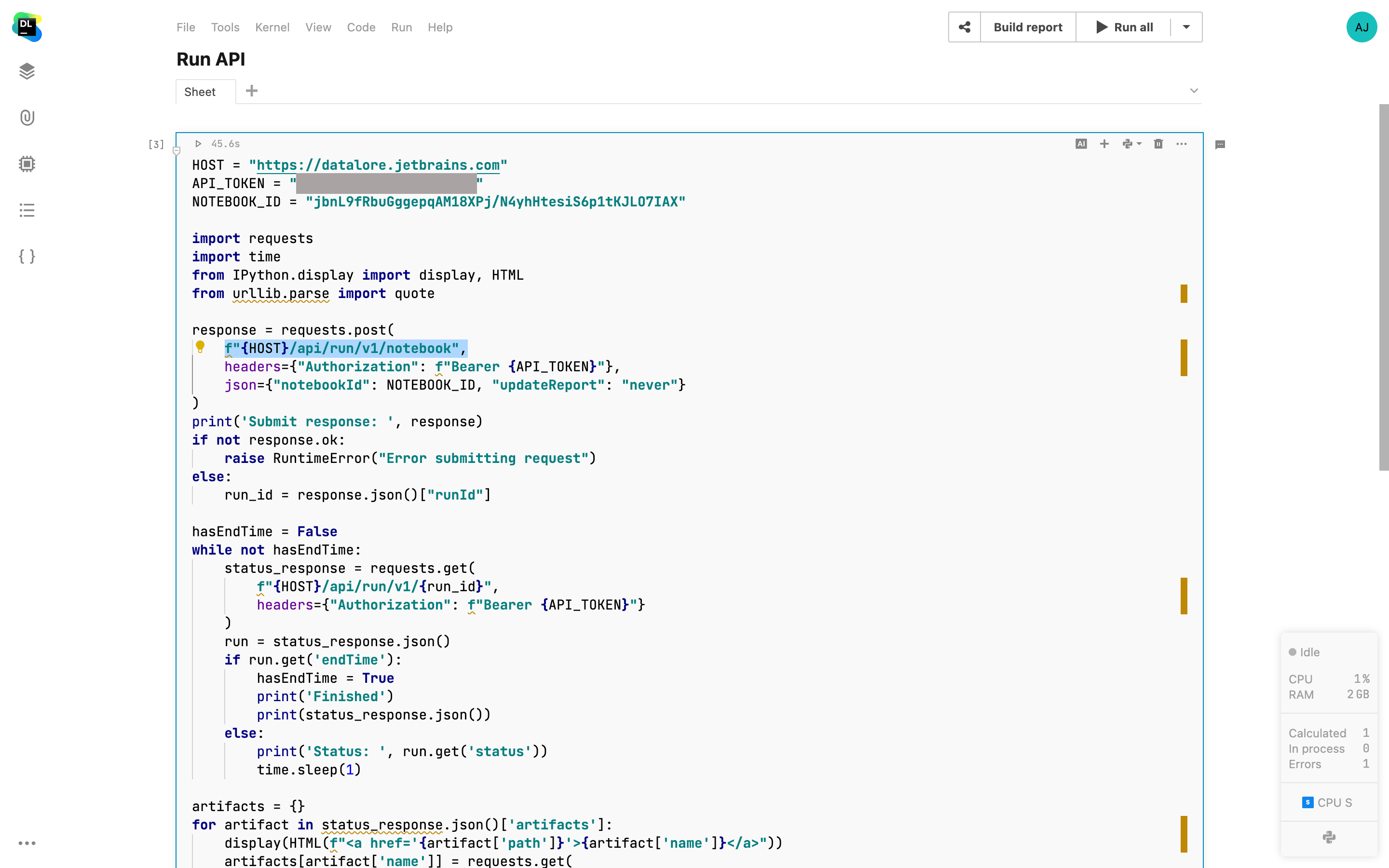
Datalore Run API
API 呼び出しで Datalore ノートブックの実行やレポートの再発行をトリガーできるようになりました。 この機能がスケジュール実行の対象に追加され、外部アプリや内部 Datalore ノートブックからオンデマンド方式でノートブックの再実行をトリガーできるようになりました。 Scheduled run(スケジュール実行)メニューから実行結果を表示することも可能です。 APIの使用方法についての詳細はこちらで見つけることができます。
ネイティブ R パッケージのサポート
R ノートブックを操作する際、install.packages がサポートする公開および非公開の R パッケージリポジトリのパッケージを Environment manager(環境マネージャー)タブでインストールできるようになりました。 Environment manager(環境マネージャー)を使うと、複数のノートブックを実行する際に一貫して同じ環境構成を維持できます。 init.sh の中で .Rprofile ファイルを作成するか、カスタムエージェントイメージを作成することで、カスタムリポジトリを構成することが可能です。
クラウドバージョンでは引き続き conda インストールがデフォルトとなりますが、Enterprise をご利用のお客様は R カーネルを使用して conda 以外のカスタムベース環境を構成することができます。 この場合、Environment manager(環境マネージャー)の検索結果に conda パッケージは表示されません。 このようなインストールの例はこちらで見つけることができます。

ノートブックのコンテンツ検索
ワークスペース全体にあるすべてのノートブックの中から特定のコードセクションや必要な情報を検索できます。 ノートブック名のほか、変数名とコンテンツも検索できるようになりました。 検索結果ではクエリがハイライト表示されます。